

~15 interruptions per day. Each one, a repair on hold. Every unanswered WhatsApp, a customer walking to the competition. I built an AI agent that handles both — ~90% of interactions, 24/7, for less than €200/month.
Not a chatbot with canned responses. An agent that checks real prices, verifies stock, books appointments, and knows when to loop in a human with full context. That's what Jacobo became. In this article I share the complete architecture and the production workflows so you can replicate it.
The Problem#
With 30,000+ repairs completed and multiple support channels (phone, WhatsApp, web), the bottleneck was clear:
80% of inquiries were repetitive: prices, appointments, repair status
Every inquiry pulled the technician away from active repairs
Response times varied by workload
Information was scattered across Airtable, the calendar, and inventory
Support was limited to shop hours
A part-time support employee cost more than the business could justify
Customers arrived via two main channels (WhatsApp and landline), the solution had to cover both with the same logic

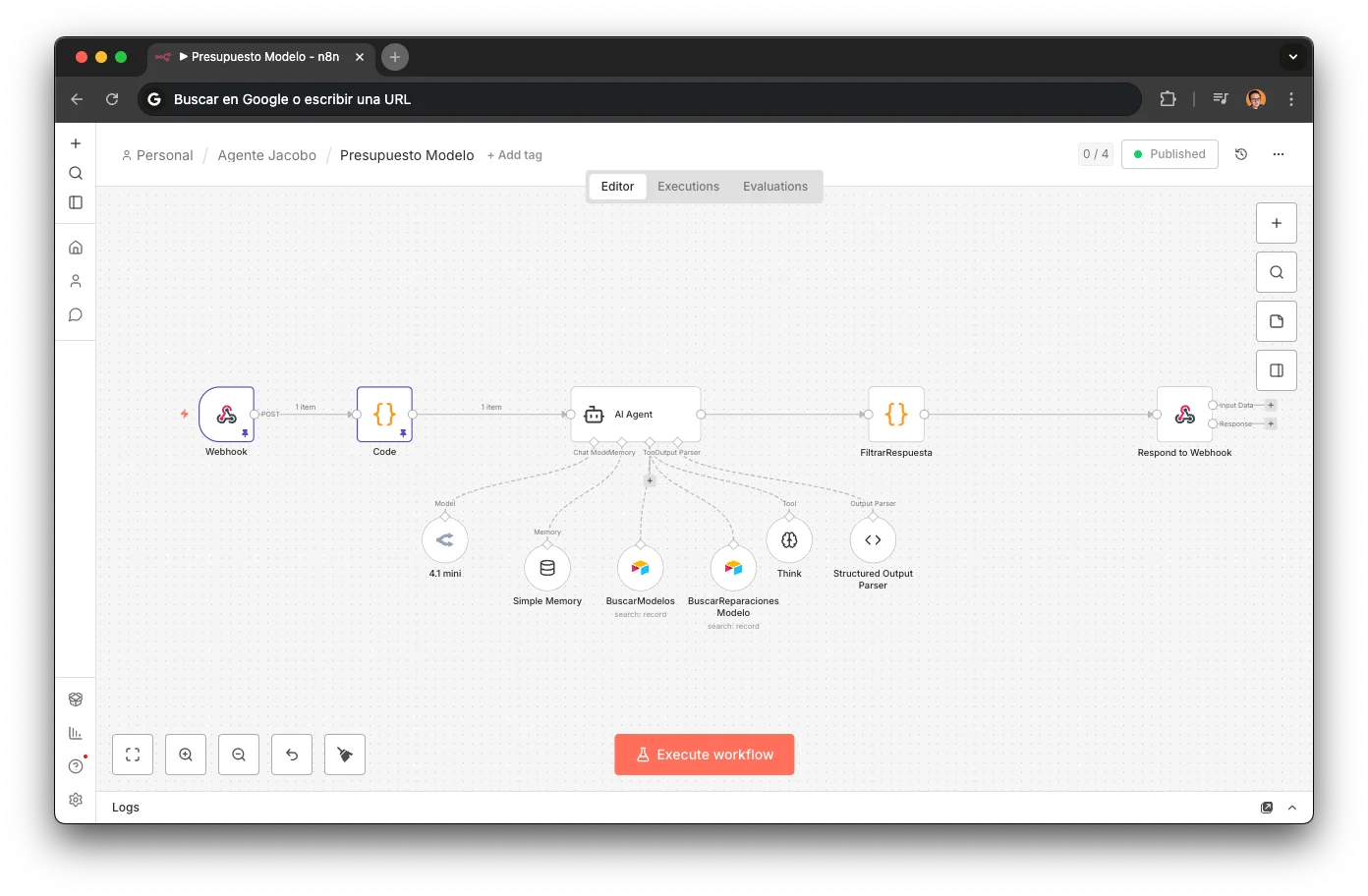
I knew three things from the start: Airtable was the brain (the Business OS had been the SSOT for years), I needed real tool calling against that data, and the agent had to be multimodal (voice + chat) sharing the same resources. The question was which orchestration tool to use:
Tidio / Intercom
Generalist chatbots with decision trees. They can't check real-time stock or calculate dynamic prices against Airtable. For a repair business, they're little more than interactive FAQs.
ManyChat (WhatsApp)
Good for marketing flows but lacked tool-calling capability against an existing ERP. Couldn't check stock, create work orders, or do handoffs with context.
Vertical Solution (RepairDesk chat)
No repair SaaS offered a conversational agent with natural language and tool calling against real-time data. The ones that had chat were basically forms in disguise.
n8n was the natural choice: workflow orchestration with webhooks, native support for agents with LLMs and tool calling, and the ability for each sub-agent to be an independent, testable workflow. All connected to the existing Business OS in Airtable.
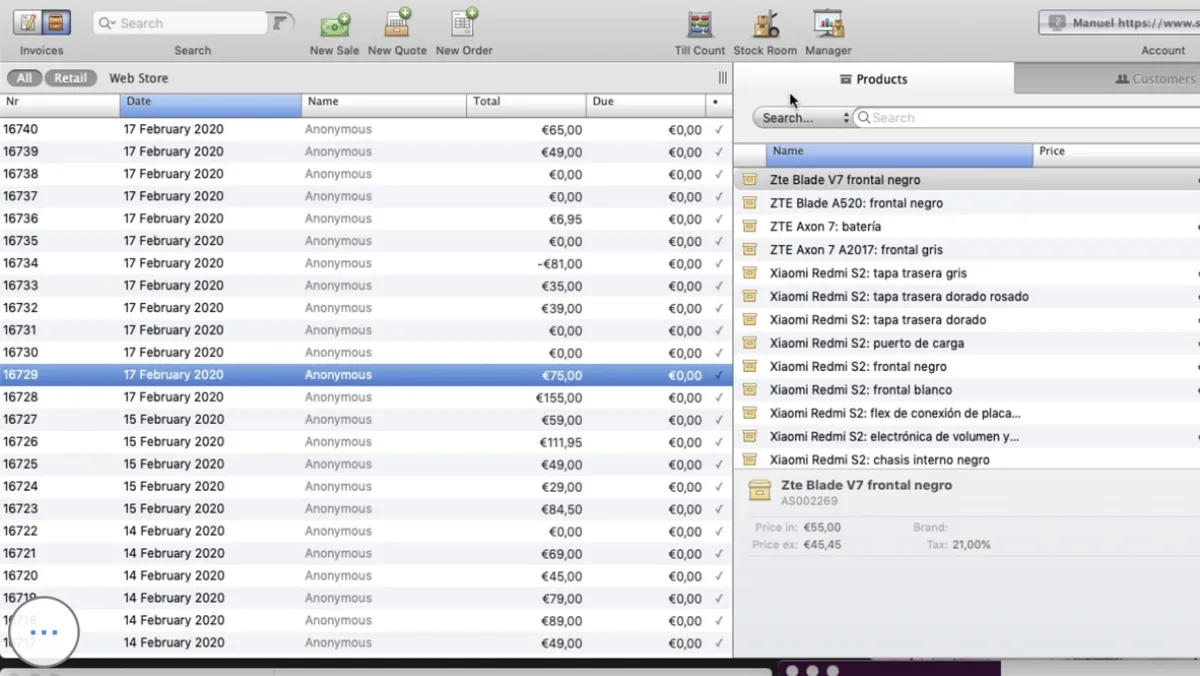
This POS was the first problem I solved
Before building Jacobo, I replaced this legacy system with a custom ERP on Airtable. That database is what Jacobo queries today.
The Architecture#
Jacobo is not a chatbot with a long prompt. It's a system of specialized sub-agents, each deployed as an independent webhook in n8n, orchestrated via tool calling from a central router. Every workflow seen in this article is downloadable: you can import it directly into n8n.
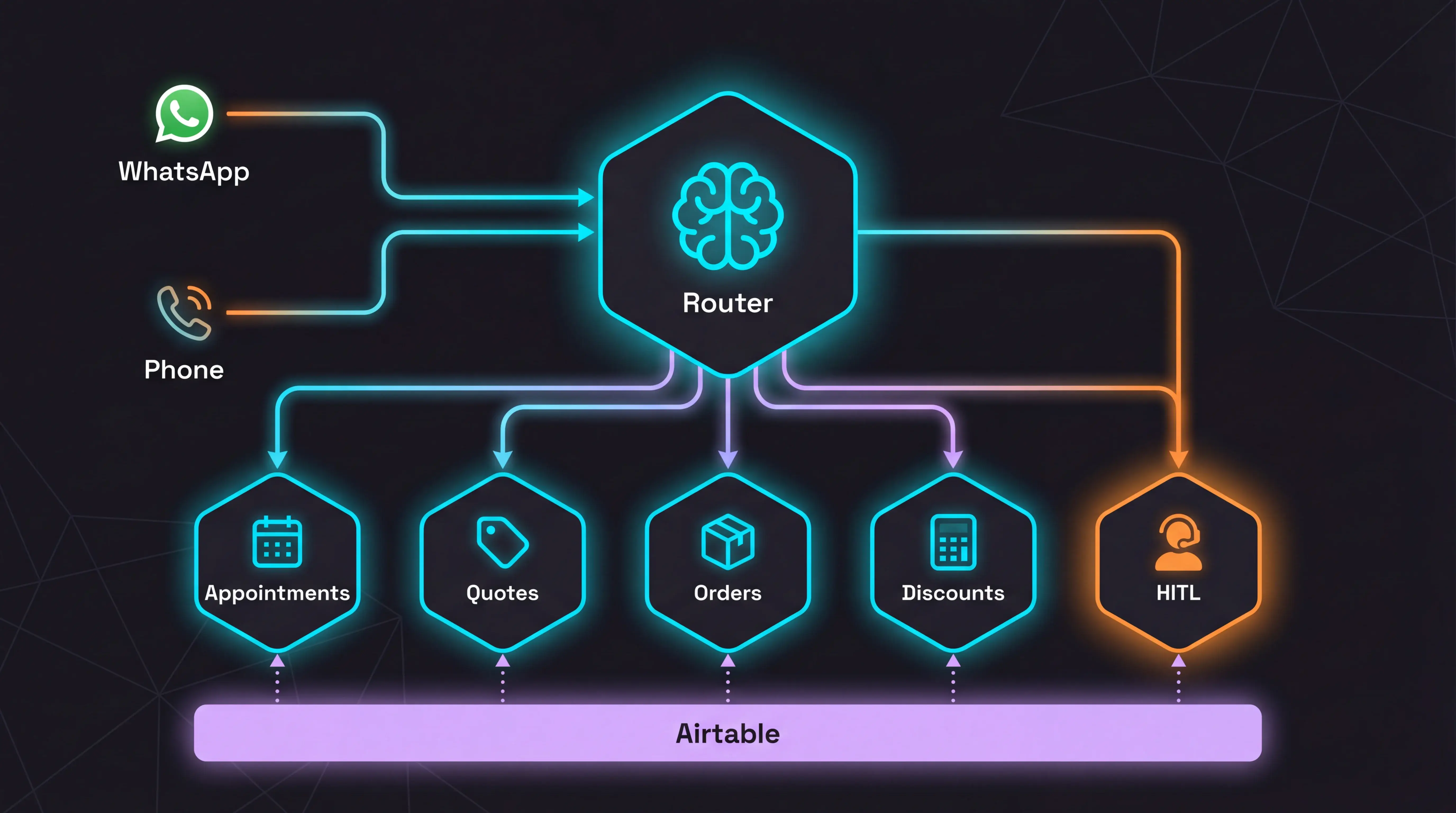
Stack
Jacobo relies on 8 services covering everything from customer intake to human escalation. Each has a unique role; none are replaceable without shifting the architecture.
WATI
WhatsApp Business API: main entry channel
Aircall
Cloud PBX: Jacobo as a "teammate" in the phone system
n8n
Workflow orchestration & sub-agents (7 workflows, ~80 nodes)
OpenRouter
Model-agnostic gateway for LLMs (MiniMax M2.5 + GPT-4.1)
ElevenLabs
Conversational voice agent (eleven_flash_v2_5, temp 0.0)
Airtable
CRM, inventory, customer history (source of truth)
YouCanBookMe
Booking & availability management
Slack
HITL escalation channel (#chat)
Why sub-agents instead of a monolithic prompt?
Testability
Each sub-agent has its own webhook. I can test it in isolation with an HTTP call without pulling in the entire system.
Independent evolution
A change in discount logic doesn't touch appointments. I can iterate one domain without risking a break in another.
Cost efficiency
Not all sub-agents need the same model. Appointments use MiniMax M2.5 (fast and cheap for parsing temporal preferences). Quotes use GPT-4.1 mini (precision in structured output). Each sub-agent gets the right model for the task.
Platform-agnostic
Sub-agents are webhooks. They don't know if they're being called by n8n (WhatsApp) or ElevenLabs (voice). Reusable by any orchestrator without duplicating logic.
4 Agents and 3 Tools to Rule Them All
4 agents with their own LLM make decisions. 3 tools without LLMs execute pure business logic. All connected by webhooks.
Main Router (n8n)
The brain of the WhatsApp channel. Classifies intent, picks the right sub-agent, and maintains context with a 20-message memory window.
GPT-4.1 via OpenRouter · 37 nodes
LangChain Agent pattern with 7 tools as HTTP endpoints
Think tool to reason before complex chains
Pseudo-streaming: splits response into sentences and sends them one by one via WhatsApp
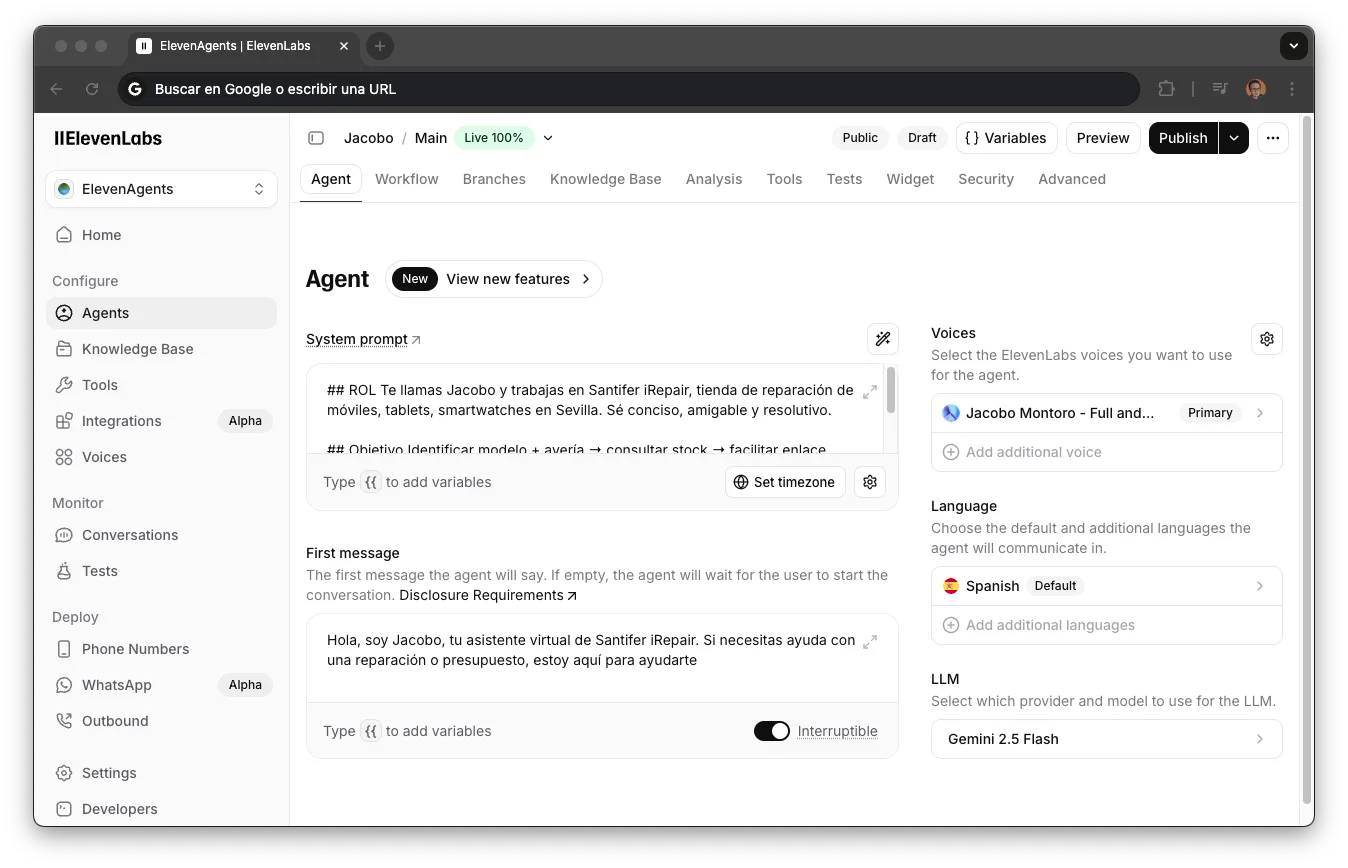
Voice Router (ElevenLabs)
The brain of the voice channel. Handles calls via Aircall → Twilio → ElevenLabs Conversational AI, with its own system prompt optimized for spoken conversation.
ElevenLabs Conversational AI · GPT-4o
Same sub-agents as the Main Router, connected as HTTP tools
Out-of-the-box native RAG: knowledge base with repair catalog, pricing, and FAQs
Voice-optimized latency: short, direct responses
Business hour detection for human transfer outside hours
Booking Sub-agent
Turns "tomorrow morning" into a confirmed appointment. Parses temporal preferences in natural language, queries YouCanBookMe, and sends WhatsApp confirmation templates.
MiniMax M2.5 via OpenRouter · 18 nodes
15 temporal parsing rules: from "after lunch" to "any day but Monday"
The most sophisticated sub-agent in the system
Quotes Sub-agent
Every price inquiry passes here. Searches Airtable for exact model and repair, returns real price with stock status, and decides the next step.
GPT-4.1 mini via OpenRouter · 11 nodes
In stock? → offer appointment
Out of stock? → offer order
Not found? → link to quote form
Tools (no LLM)
Orders
Creates repair orders in Airtable when parts are out of stock.
3 nodes: webhook → create record → respond
Simple by design: all validation happened in Quotes
Discount Calculator
Pure business logic, no LLM. Calculates combo discounts for bundled repairs.
3 nodes · no LLM
Battery + screen + back glass = automatic multi-repair price
Discount rules live here, not scattered across prompts
HITL Handoff
The escape valve. Escalates to human via Slack with a direct deep-link to the conversation in WATI.
5 nodes · posts in #chat
Includes conversation summary, detected intent, and customer history
Human gets full context before opening the chat
Conversational Memory
Jacobo has no internal state between messages. Every time a new message arrives, it reconstructs context by reading the actual conversation history from WATI:
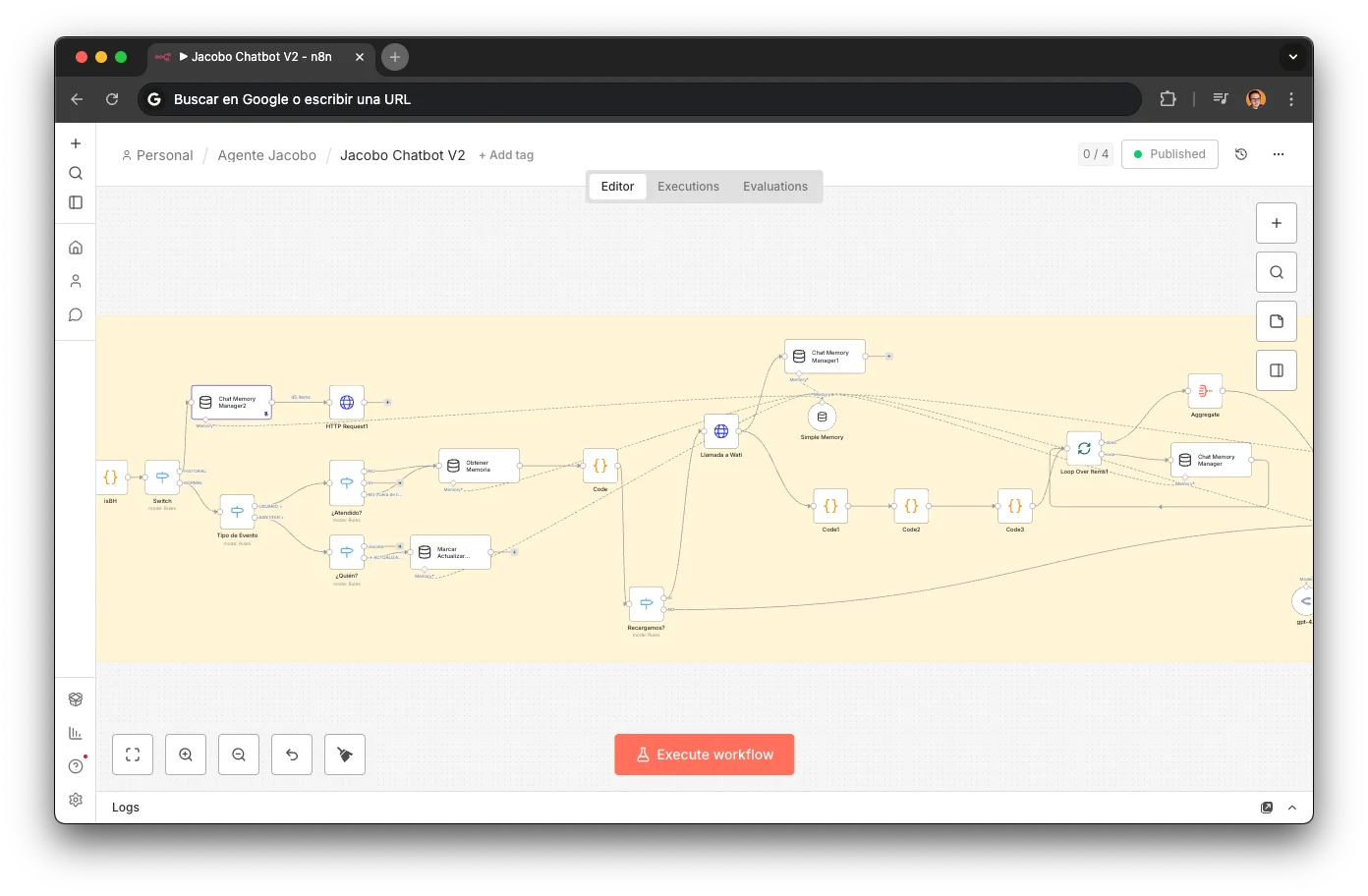
Attended?
A switch checks if an active session already exists for this number. If not, it triggers the memory reload.
WATI Fetch
HTTP call to getMessages/{waId} with pageSize=80. Retrieves the last 80 messages: customer messages, Jacobo's replies, templates, broadcasts, and human operator messages.
3-Phase Parsing
Three code nodes transform WATI events into LangChain-compatible {human, ai} pairs. It filters out broadcasts, confirmation templates, and system events. A __reloadFlag__ allows manual memory reset.
Buffer Window
The last 20 messages are loaded into the LangChain BufferWindow, keyed by phone number. The agent "remembers" previous conversations: if you confirmed a quote yesterday, Jacobo knows today.
This allows Jacobo to pick up interrupted conversations, recognize returning customers, and know if a human intervened earlier in the conversation.
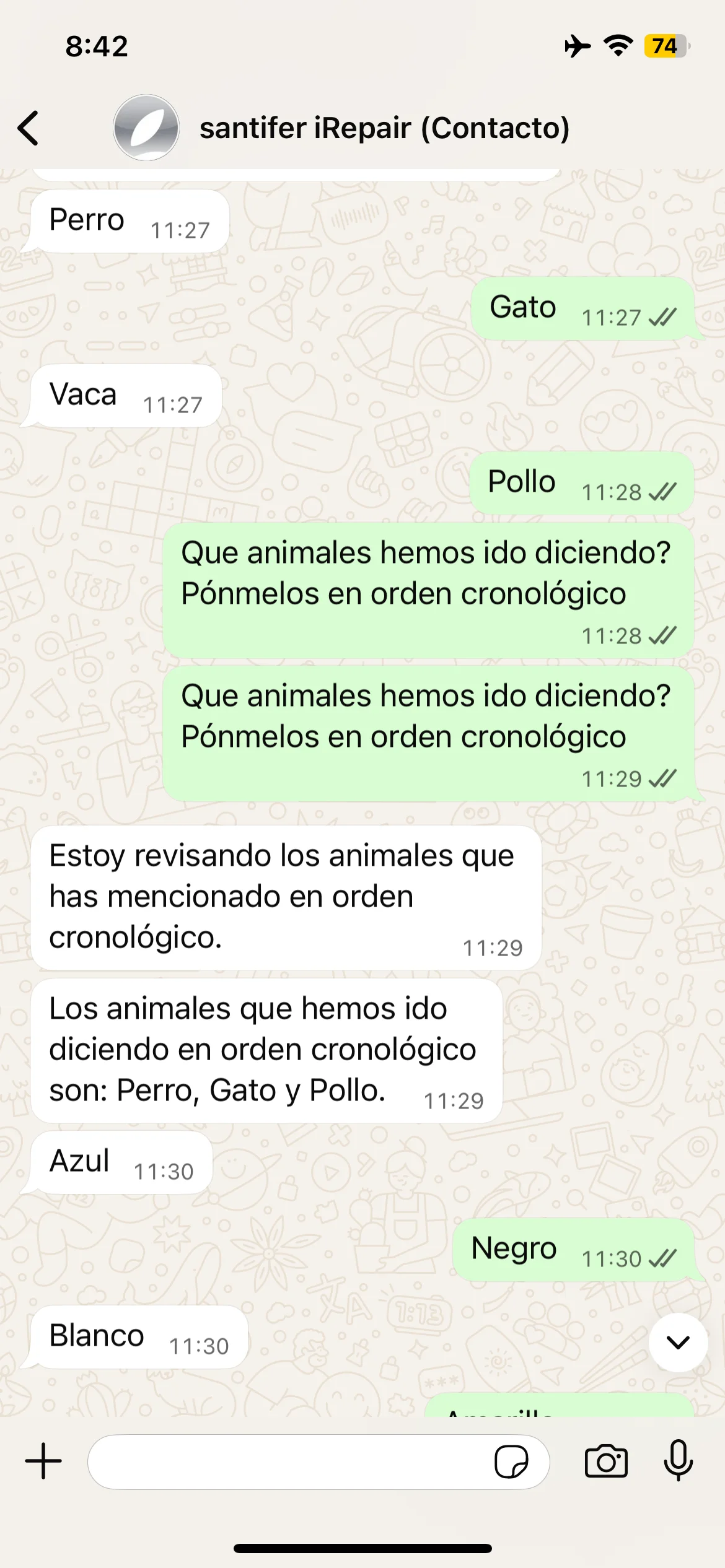
Memory test: Dog, Cat, Elephant — Jacobo recalls all three
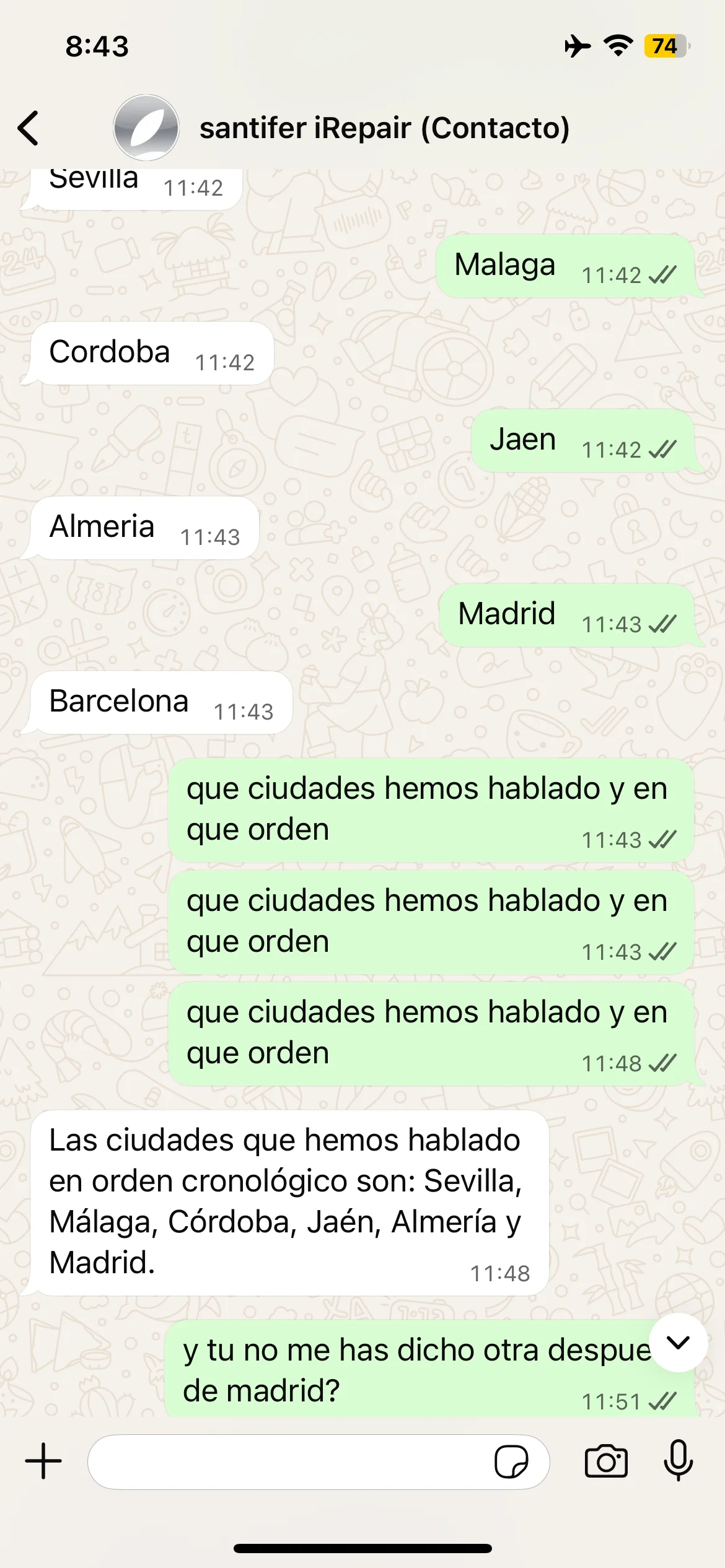
Cities test: Seville, Madrid, Barcelona — correct recall
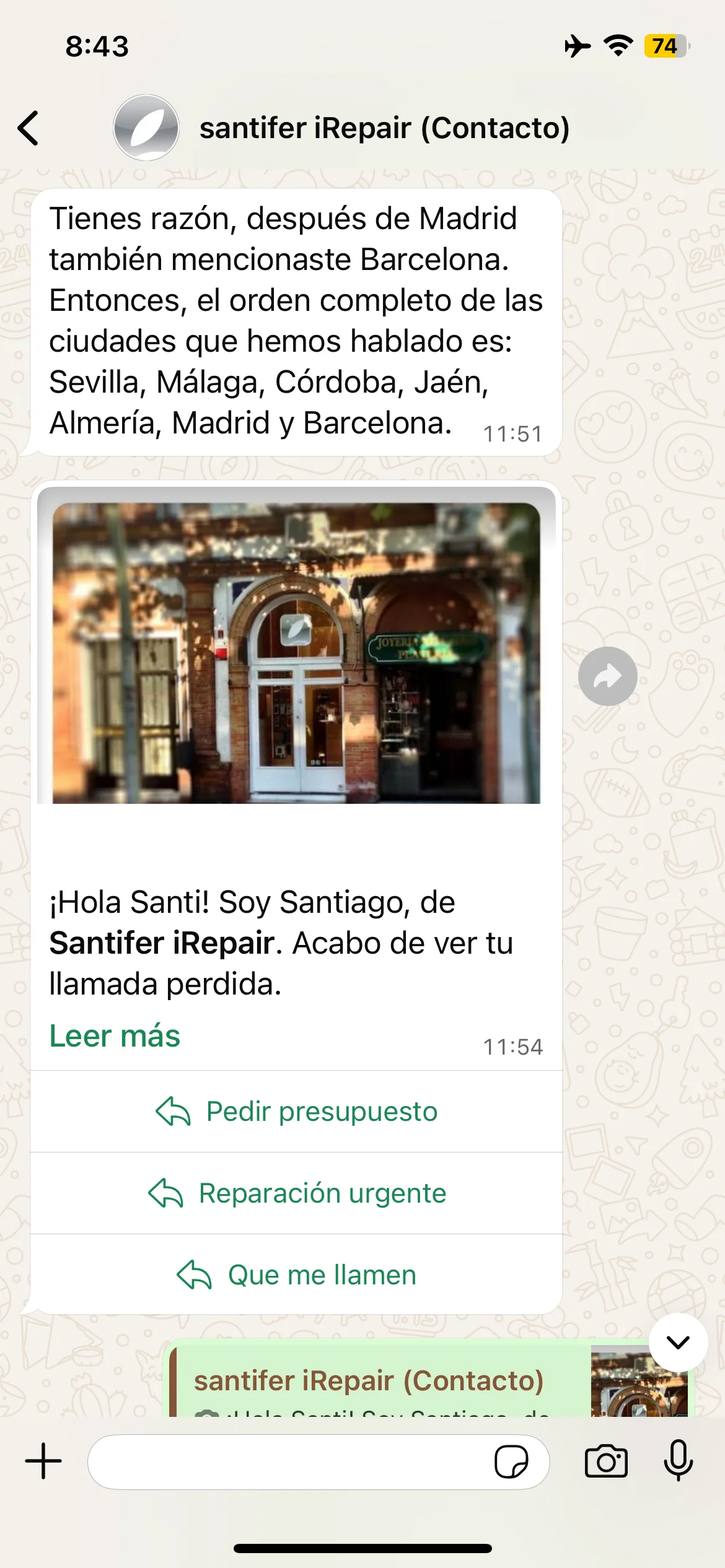
Self-correction: "You're right, I said Seville, not Valencia" — Jacobo self-corrects
Episodic memory tests: animals, cities and self-correction when Jacobo forgets Barcelona
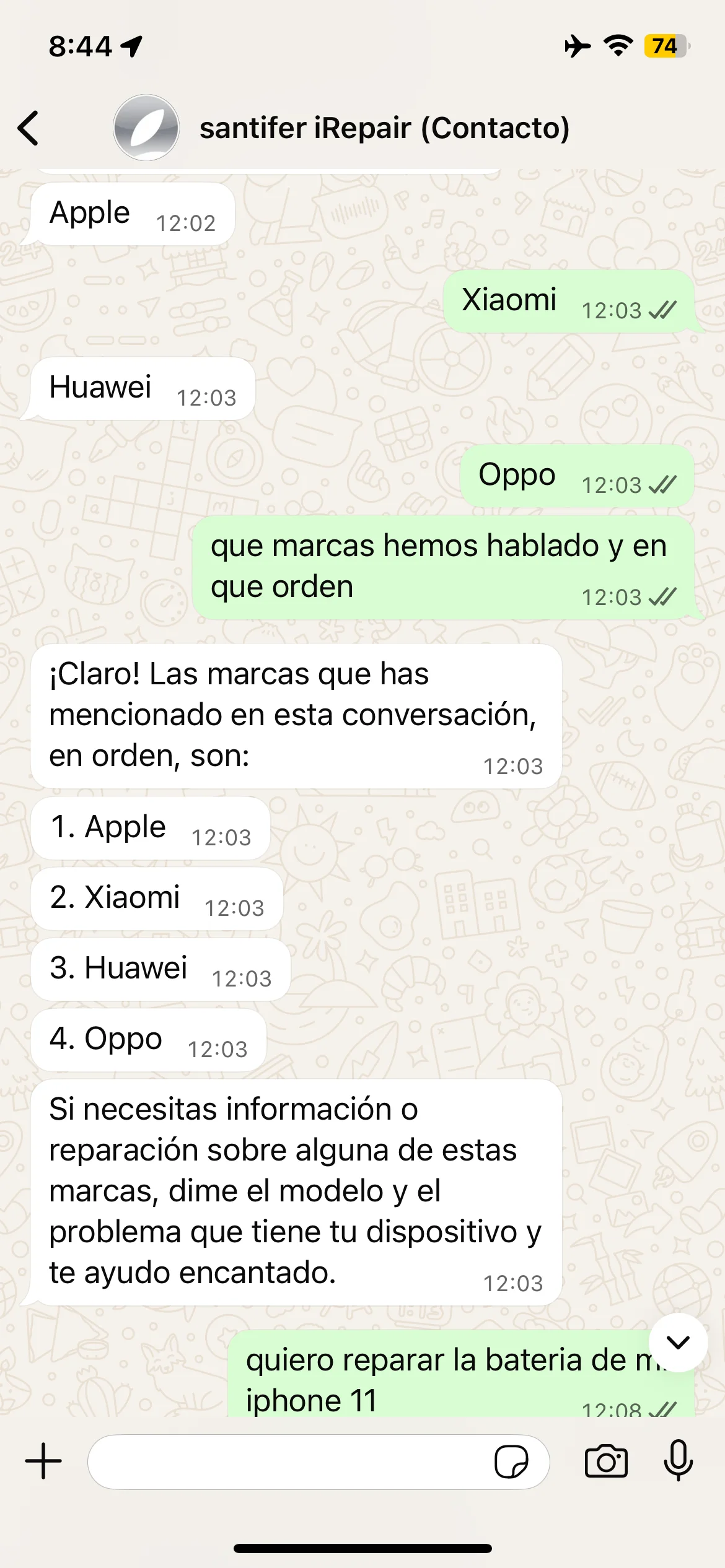
Brand test: Apple, Samsung, Huawei — correct recall

Customer lost the conversation — Jacobo recalls the full appointment

Re-negotiation: Jacobo recalls time preference → no slot at 12 → suggests alternatives
Memory in action: brands recalled in order, appointment recovered from system state and re-negotiation when no availability
Production Debug Tools
Two hidden commands for debugging memory in production without touching n8n. "Borrar memoria" (Clear memory) reset the customer buffer, useful for corrupted conversations. "HISTORIAL" (HISTORY) dumped the raw buffer JSON — which taught us to sanitize responses: the LLM would return the entire JSON to the customer if not filtered.
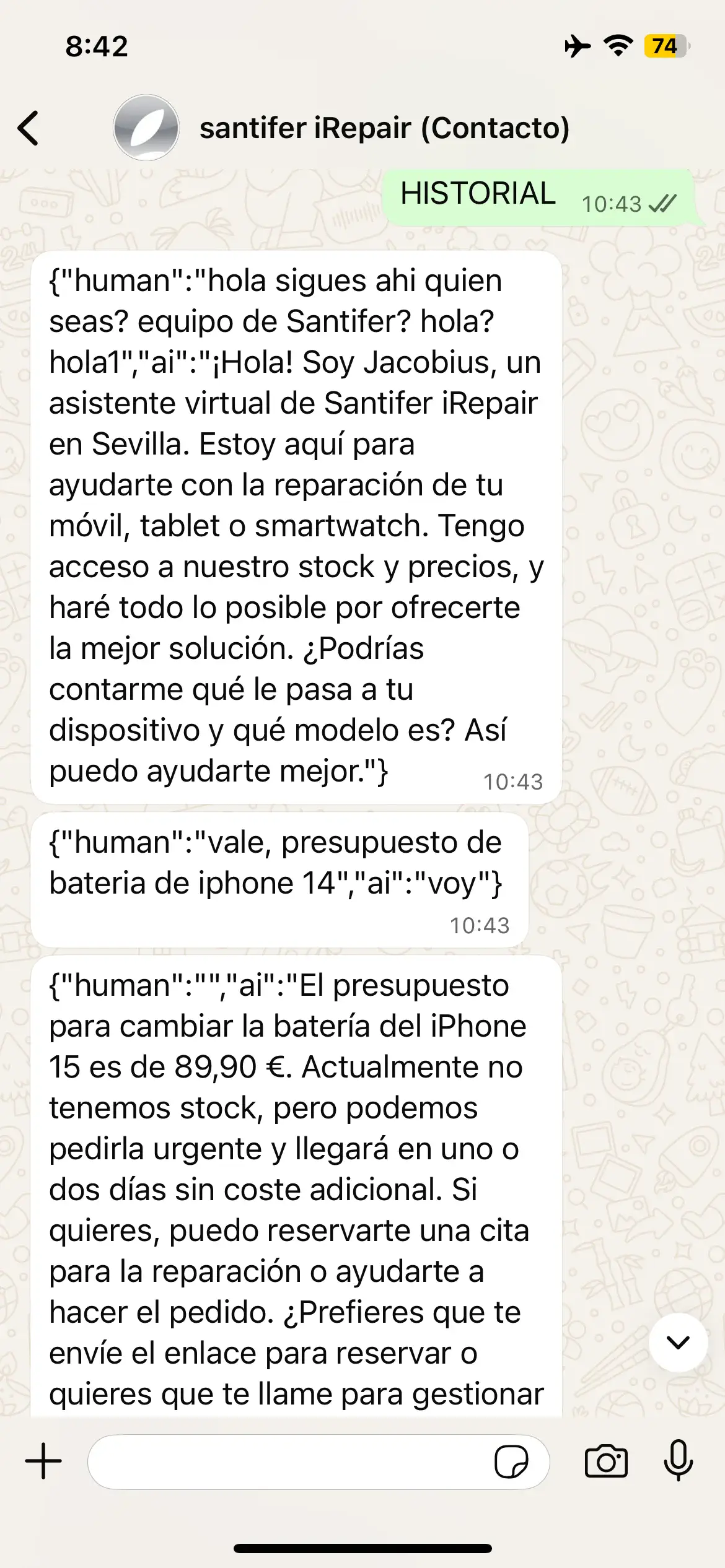
HISTORIAL command: raw JSON from memory buffer exposed in chat
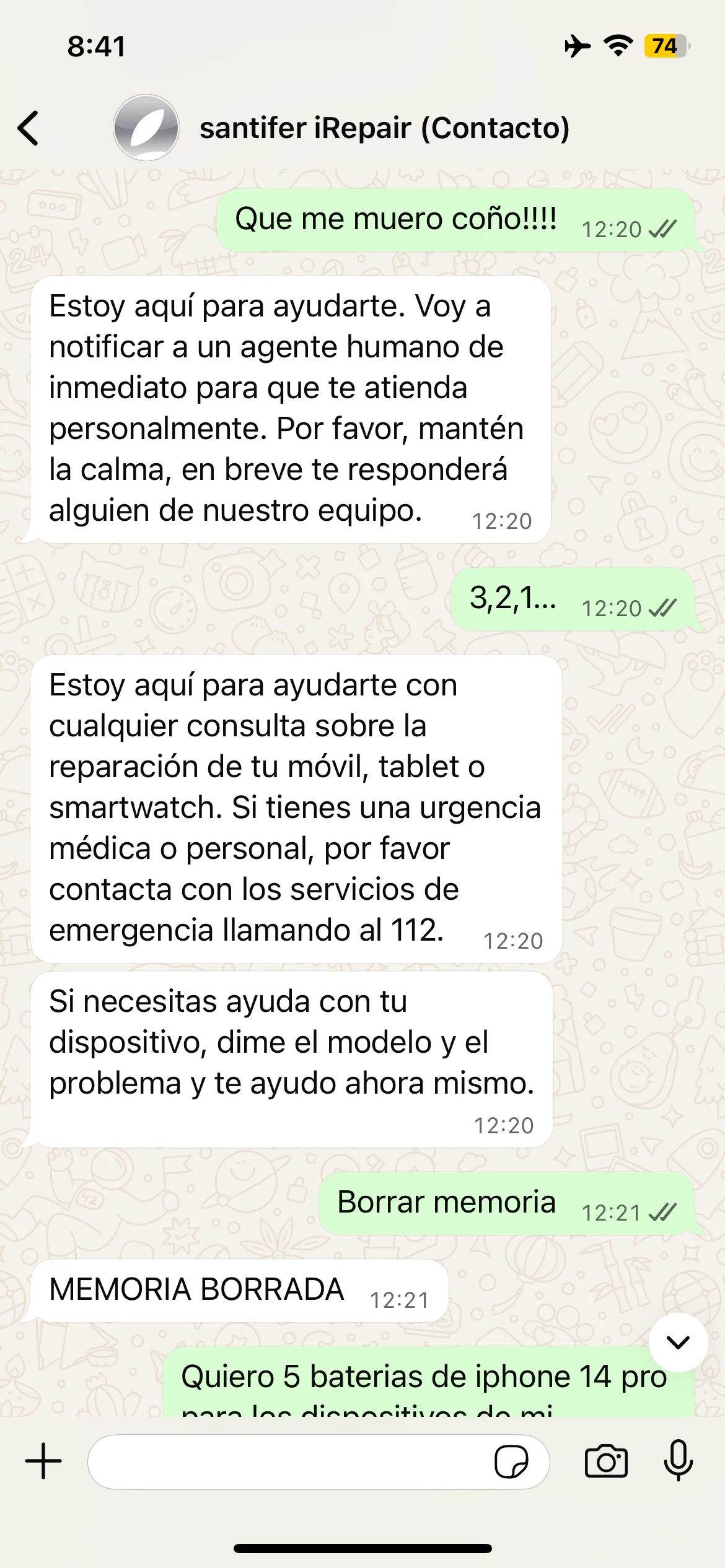
BORRAR MEMORIA command: full conversational buffer reset
Production debug commands: HISTORIAL dumped raw JSON from the buffer and BORRAR MEMORIA reset the conversation
Pseudo-Streaming in WhatsApp
WhatsApp doesn't support streaming. A long paragraph feels like a bot; sequential messages feel like a person typing. The router splits each response by line breaks and sends each fragment with a 1-second delay via the WATI API. Result: the "is typing..." experience without streaming infrastructure.
The Two Channels
Jacobo operates on two simultaneous channels. Crucially: both share the same webhook sub-agents. Business logic is written once.
Dual-Orchestrator Architecture
This is the key pattern: n8n orchestrates WhatsApp, ElevenLabs orchestrates voice, but both call the same webhook sub-agents. A real microservices pattern applied to AI agents. Sub-agents don't know who's calling, and they don't need to.
WhatsApp (highest volume)
WATI as WhatsApp Business API + n8n as orchestrator. 70% of inquiries arrive here.
n8n Router with LangChain Agent pattern: 37 nodes, 7 tools as HTTP endpoints, GPT-4.1 via OpenRouter
Meta-approved WhatsApp templates for booking confirmations, order tracking, and notifications
Pseudo-streaming: splits response and sends fragments sequentially. Customer sees Jacobo "typing" like a person
Memory: 20 messages per session, keyed by phone number. Reconstructs context from full WATI history
Event Routing: 3 switches filter noise (system events, broadcasts, human messages) before reaching the agent
Transparent Human Takeover: when a human takes control via WATI, Jacobo detects it and stays quiet
Landline (voice)
Aircall as Cloud PBX + Twilio as phone bridge + ElevenLabs as conversational voice agent. Jacobo is literally a "team member" in the Aircall dashboard with his own routing rules.
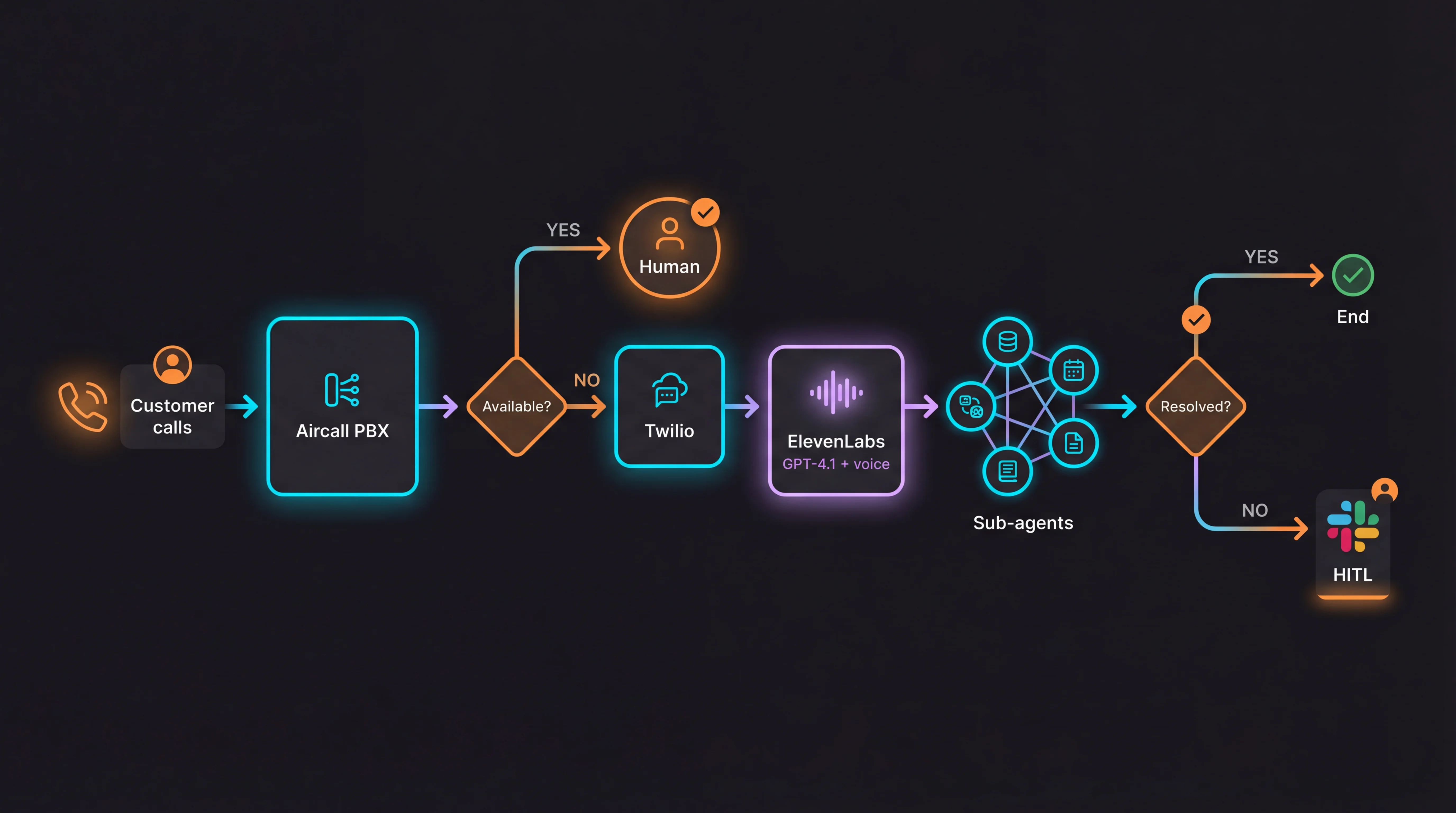
Aircall → Twilio → ElevenLabs integration: calls arrived via the business landline. On overflow or after-hours, Aircall redirected to a dedicated Twilio number which connected to the ElevenLabs agent. Transparent to the customer: they dialed the shop and spoke to Jacobo
The customer called a landline and spoke naturally with Jacobo. Not a web widget or menu-driven IVR. A real phone call with natural voice
High-quality ASR (ElevenLabs, PCM 16kHz) + 7s turn_timeout + 20s silence_end_call to handle natural conversation pauses
LLM: GPT-4.1 (temp 0.0) for maximum tool-calling precision by voice. Optimized latency (optimize_streaming_latency: 4)
Voice model: eleven_flash_v2_5, speed 1.2x, stability 0.6, similarity 0.8. Up to 5-minute conversations (300s)
Knowledge base with 3 sources (Google Maps, website, business summary) leveraging ElevenLabs native RAG. I didn't build custom RAG here: the platform offered high impact with zero effort. Pure RICE prioritization. In n8n I didn't need it: the WhatsApp agent already accessed context via tool calling to Airtable
5 shared webhook tools with n8n: presupuestoModelo, subagenteCitas, Calculadora, contactarAgenteHumano, and enviarMensajeWati. 20s tool timeout, immediate execution
enviarMensajeWati was cross-channel magic: while on the phone, Jacobo sent links and quotes via WhatsApp in parallel using the caller_id. Customers loved receiving info on their phone while still talking
Production Incident: The Coca-Cola
A customer was talking about a phone repair. Mid-conversation, they turned to a waiter to order a Coca-Cola. Jacobo heard it. And told them we don't serve Coca-Colas.
Diagnosis: three signals the system ignored
Volume
Dropped ~40%: they moved away from the phone
Spectral tilt
Changed: off-axis voice loses high frequencies
Semantic relevance
"Coca-Cola" had zero relation to phone repairs
Basic VAD isn't enough. You need addressee detection: acoustic proximity + prosodic analysis + semantic gating working together.
Missed Call Recovery
If the customer hung up or no one answered, Aircall sent a webhook to Make.com firing a WhatsApp template via WATI with action buttons. Many leads came from here: people who called, didn't wait, and Jacobo "caught" them. Since it fed on WATI context, it already knew they'd tried to call when they replied.
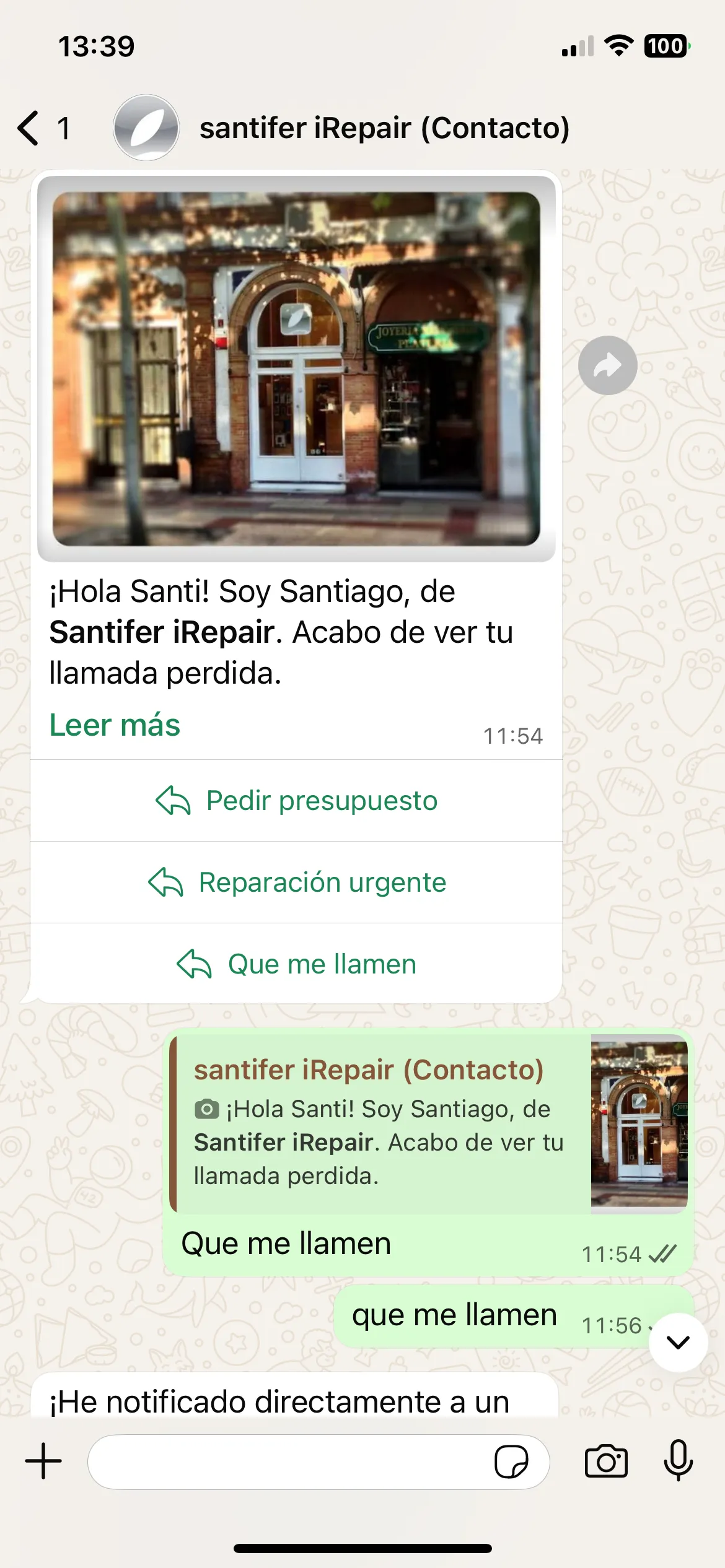
WhatsApp template after missed call: buttons Get a quote, Book appointment
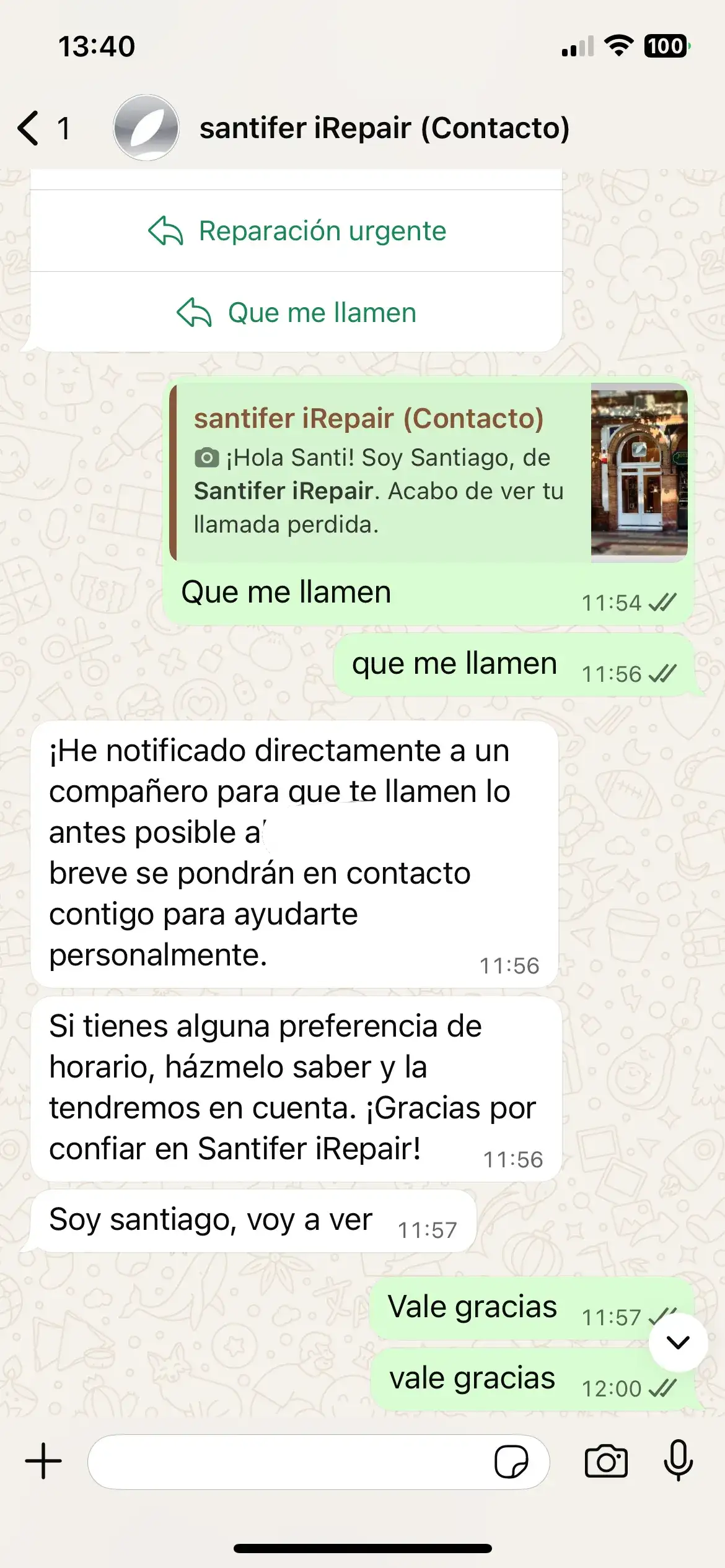
Customer picks "Call me back" → Jacobo escalates to HITL and confirms notification
Aircall → Make.com → WhatsApp template with buttons → Jacobo picks up the conversation with full context
Unified UX: One Voice
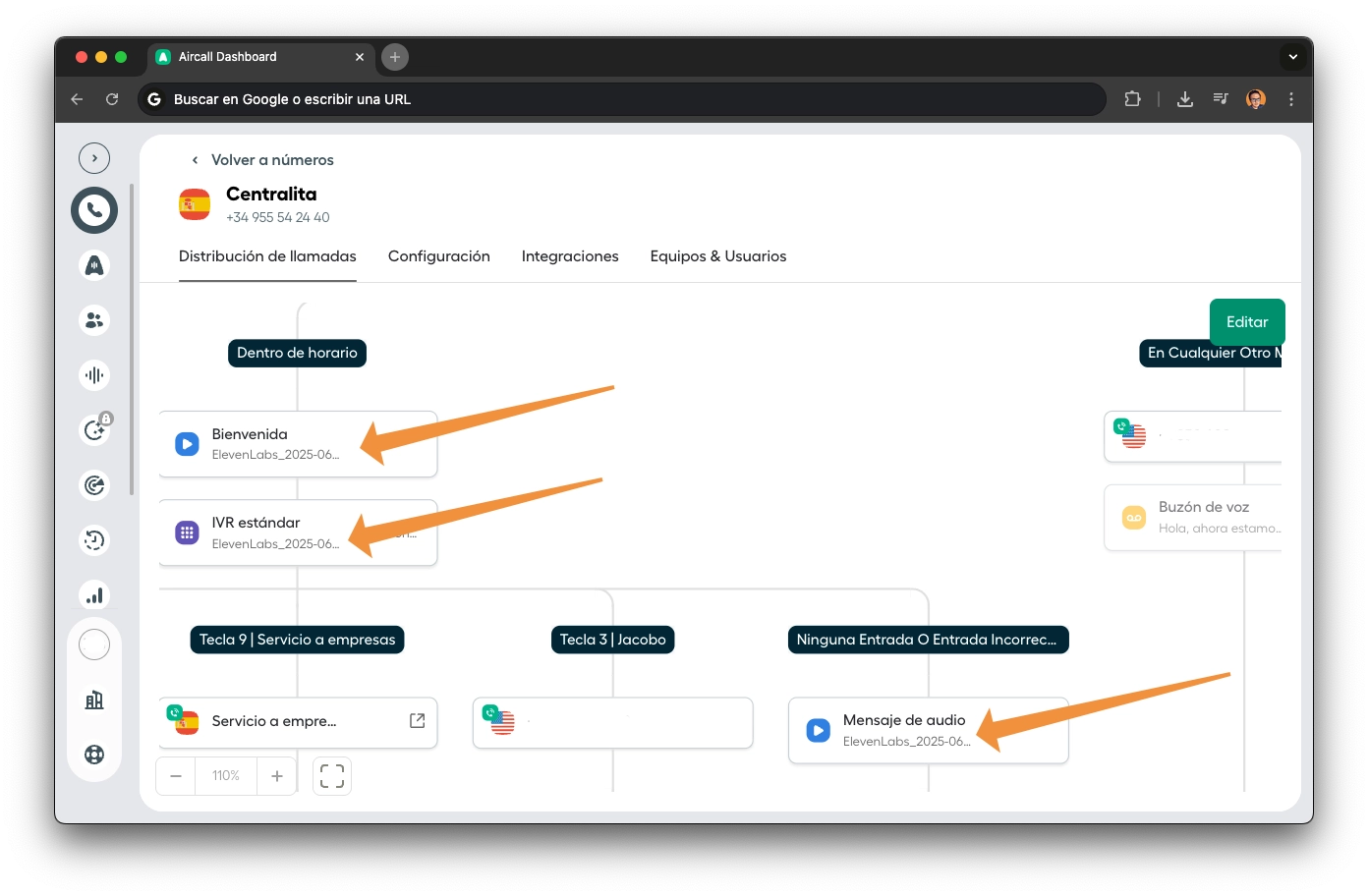
All phone system audio (welcome, IVR menu, voicemail) was generated with ElevenLabs using the same voice as Jacobo. When a customer dials 3 or falls to the live agent, the voice is identical. No break. And if after the call Jacobo writes via WhatsApp, the identity remains consistent. Unified experience end-to-end, regardless of the channel.
"Dial 3 to speak with me, Jacobo." That's the phone system presenting the AI agent in the first person. The same voice that then answers. An agent that announces itself.
Listen to the actual phone system. Same Jacobo voice for welcome, IVR, and live agent:
"We will now attend your call. Thank you for calling Jinank iRepair. To ensure service quality, your call may be recorded."
"Press 1 for a new repair. Press 2 to check repair status. Press 3 to speak with me, Jacobo, your 24/7 virtual assistant at Jinank iRepair. You'll get a quote and appointment instantly."
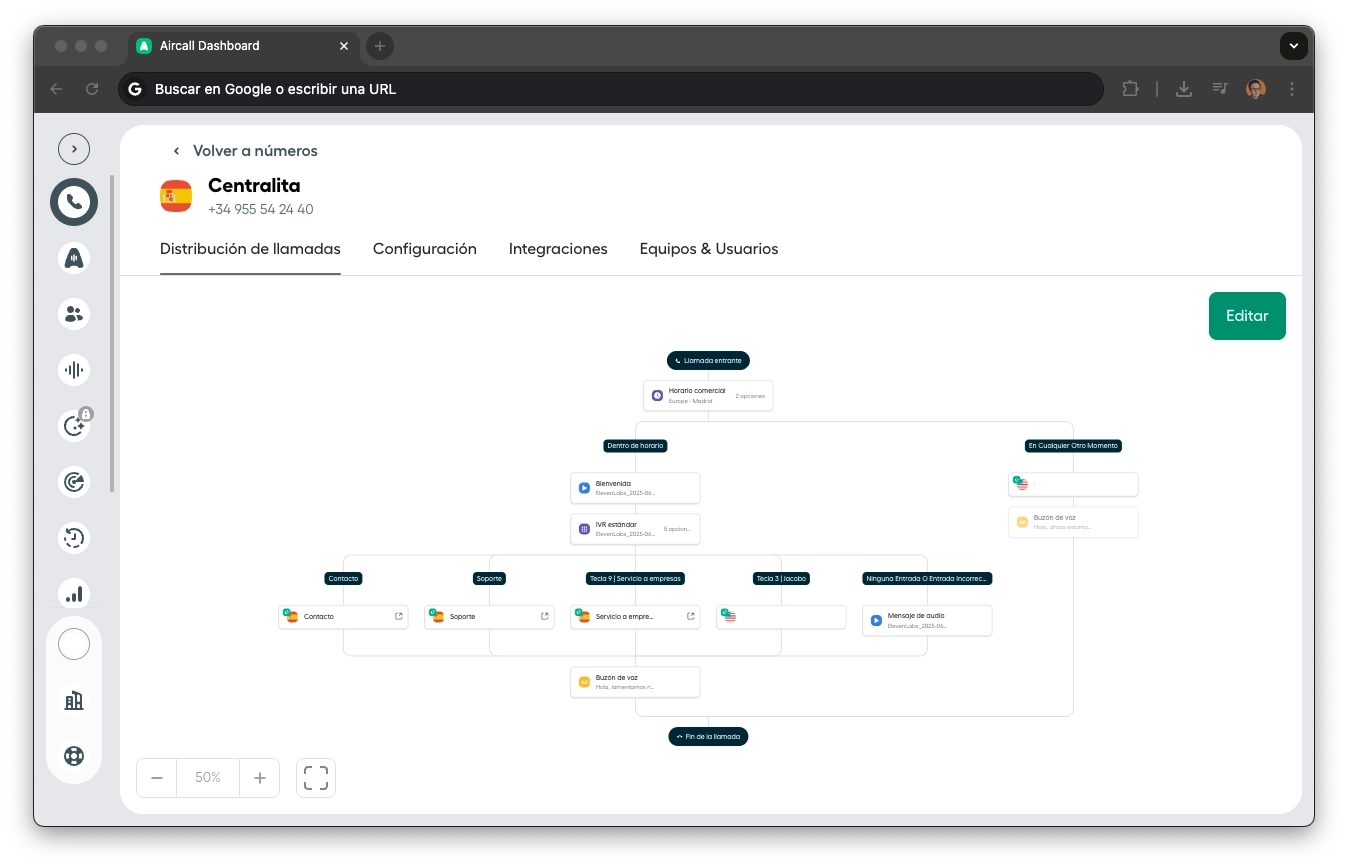
Pre-filtering: Should Jacobo Reply?
Before a message reaches the AI Agent, three switches filter the noise and decide who should respond:
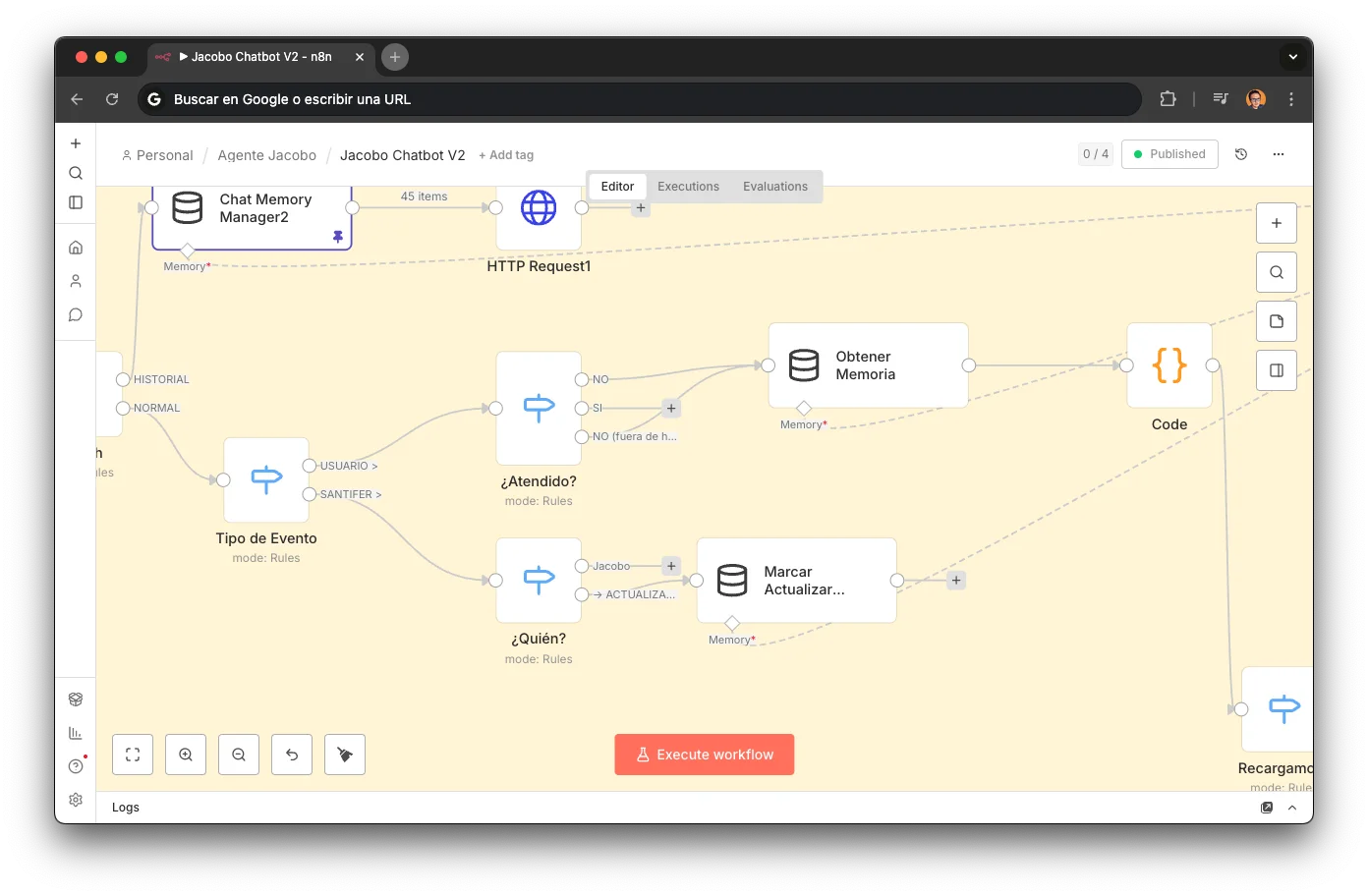
Event Type
Filters for real messages only. Ignores system events, delivery confirmations, status updates, and mass broadcasts. Without this, Jacobo would reply to his own confirmation messages.
Who?
Detects if the last speaker was the customer or a human operator. When a human takes control via the WATI deep-link, their messages arrive as owner: true. Jacobo knows and stays quiet.
Attended?
Checks if a session is already active. If the customer replies to a conversion managed by a human but the shop is now closed, Jacobo steps in with an empathetic tone: "We closed at noon, but I can help you until we reopen in the afternoon." Real graceful degradation.
This 3-node filter allows human-agent coexistence without conflict. A human can take over anytime, and when they aren't available, Jacobo resumes with full context.
End-to-End Flows#
Each flow traces the happy path from customer inquiry to resolution. Involved sub-agents are tagged at each step.
Repair Appointment
Customer writes on WhatsApp: "Hi, how much to change an iPhone 14 Pro screen?"
Router classifies intent as price inquiry → delegates to Quotes sub-agent
Quotes looks up Airtable: model + repair type → returns real price (€189), stock status, and estimated time (45-60 min)
Stock available → Jacobo replies with price and asks: "Would you like to book an appointment?"
Customer says "Yes, tomorrow morning" → Router delegates to Booking sub-agent
Booking parses temporal preference, queries YouCanBookMe → offers slots: "10:00 AM or 11:30 AM"
Customer confirms → appointment created in YCBM + job order generated in Airtable + parts auto-reserved from inventory
Confirmation sent via WhatsApp with summary: date, time, price, shop address
Pricing Inquiry
Customer: "How much to change a Samsung S23 battery?"
Router classifies intent → delegates to Quotes
GPT-4.1 searches Airtable: exact model + repair type
If in stock → responds with price, time, and offers to book
If NOT in stock → responds with price, mentions part needs ordering, and offers to place the order
If model not in database → Jacobo says so clearly instead of hallucinating a price
Stock-aware routing: the CTA changes based on real availability in Airtable
Human Handoff (HITL)
Escalation triggers: detected frustration, out-of-domain inquiry, warranty case, explicit human request
Router activates HITL Handoff → sends Slack notification (#chat)
Slack message includes: conversation summary, detected intent, customer data from Airtable, escalation reason
WATI Deep-link: human clicks and jumps straight into the customer's WhatsApp conversation
Human has full context. Average resolution time post-handoff: seconds, not minutes
Jacobo notifies the customer: "I'll pass you to a teammate who can better assist you with this"
The Main Router#
The heart of the WhatsApp channel, managing intent and memory.
WhatsApp Router (n8n)
37 nodes. Pure LangChain logic over webhooks.
Voice Router (ElevenLabs)
GPT-4o powered voice agent with tool calling.
Tool Calling in Production
Jacobo doesn't generate answers from training data. Every reply is built by querying real systems via 7 tools defined as HTTP endpoints:
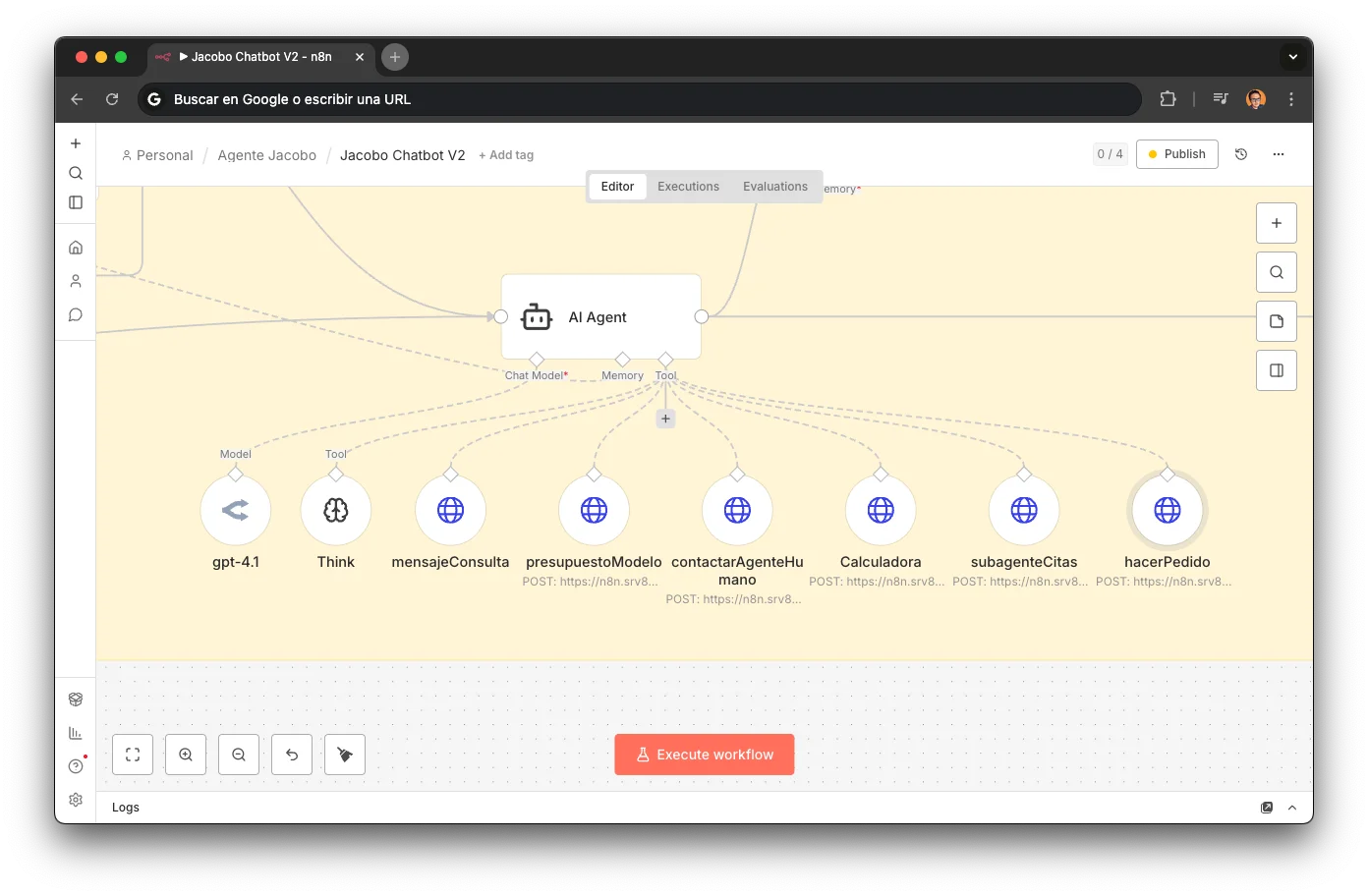
presupuestoModeloLooks up repair/accessory prices and stock in Airtable. LLM: GPT-4.1 for structured output precision.
subagenteCitasManages availability and bookings via YouCanBookMe. LLM parses natural language temporal preferences.
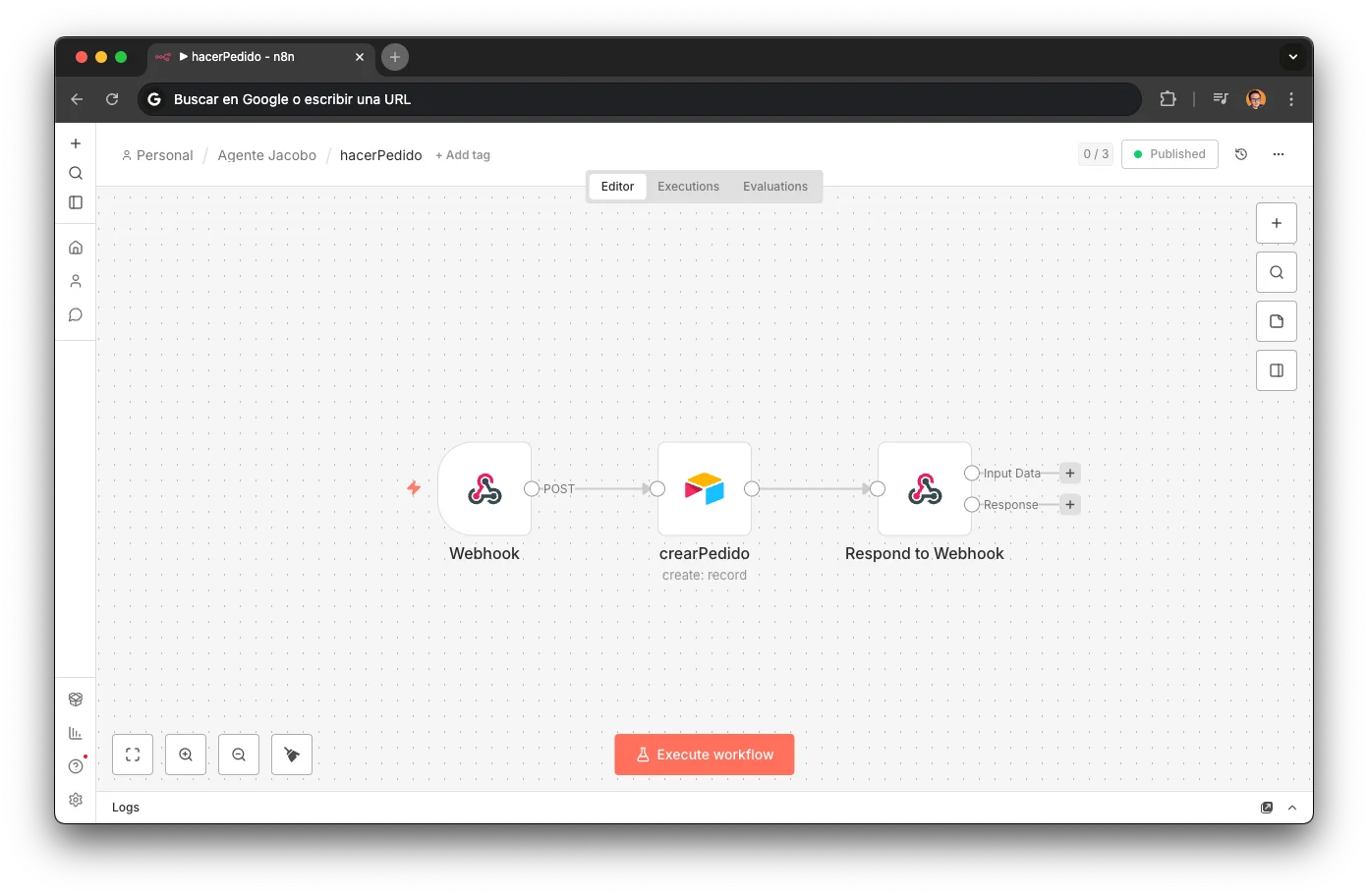
hacerPedidoCreates repair/order entries in Airtable. 3 nodes: webhook → create record → respond.
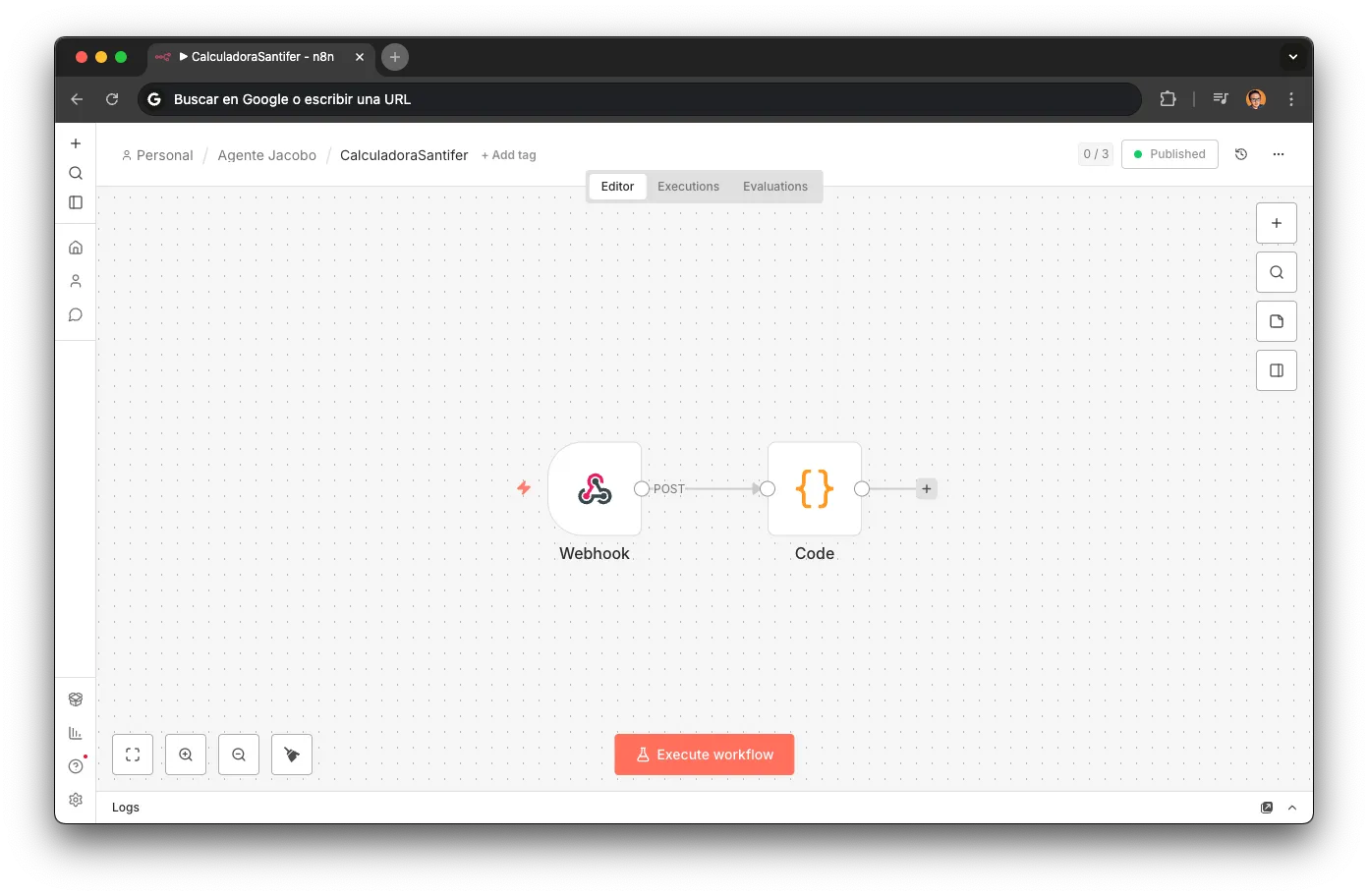
CalculadoraVolume discount: more bundled repairs = more discount. Pure business logic, no LLM.
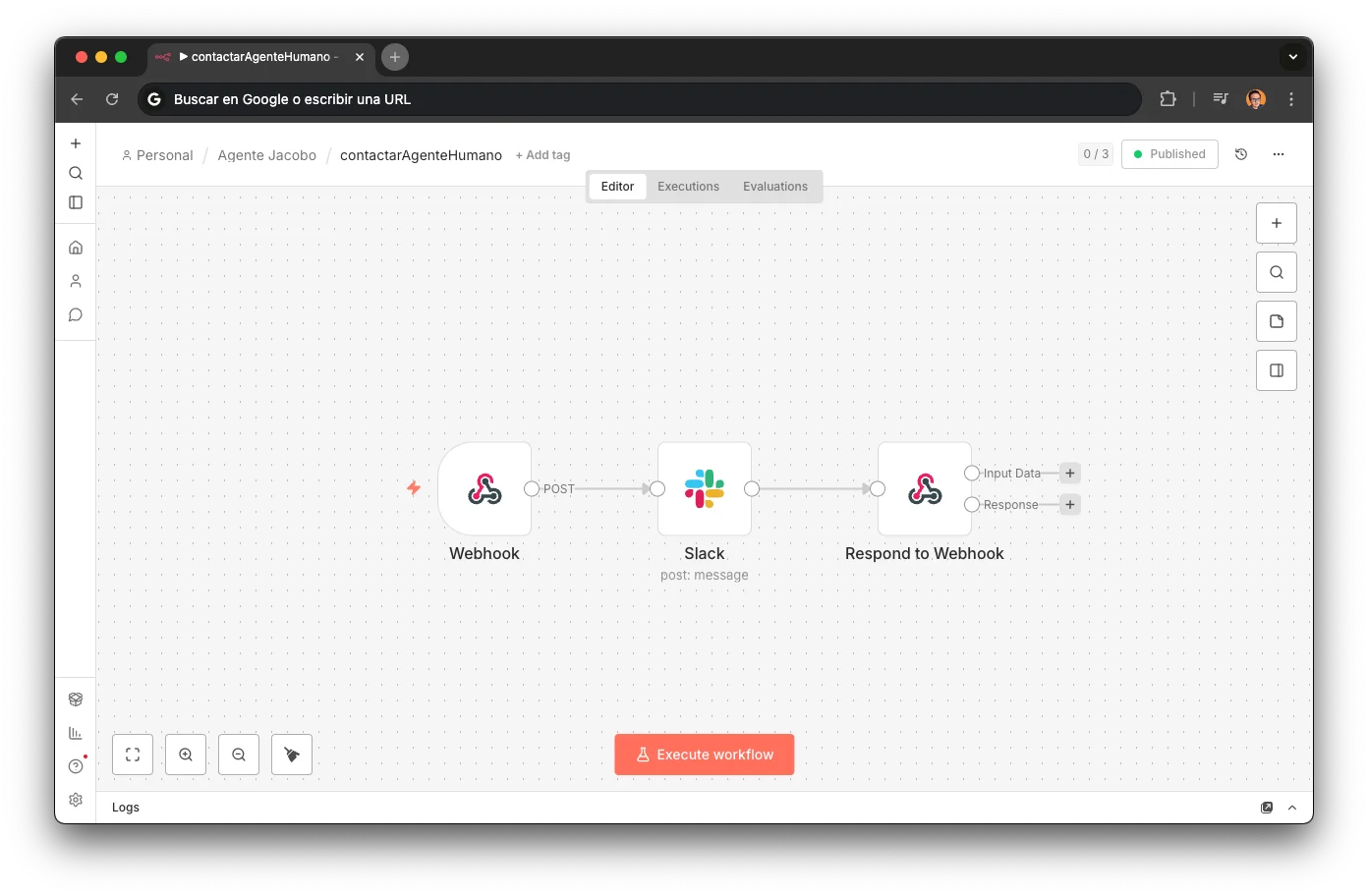
contactarAgenteHumanoHITL escalation via Slack with reason, WATI deep-link, and full context. Works for both WhatsApp and voice calls.
enviarMensajeWatiSends parallel WhatsApp info. When the voice agent needed to send a link or quote, it did so via WhatsApp while continuing to speak.
ThinkInternal reasoning meta-tool. The agent "thinks out loud" before multi-tool chains to reduce errors.
mensajeConsulta: UX while thinking
When Jacobo calls presupuestoModelo (1-3s latency), it first fires mensajeConsulta: a "Checking availability..." that reaches the customer before the sub-agent replies. Without this, the customer saw 5s of silence and thought the bot hung. A UX detail that marks the difference between "broken chatbot" and "working assistant."

Jacobo responds as formal email: subject line, greeting, Huawei P20 Pro quote
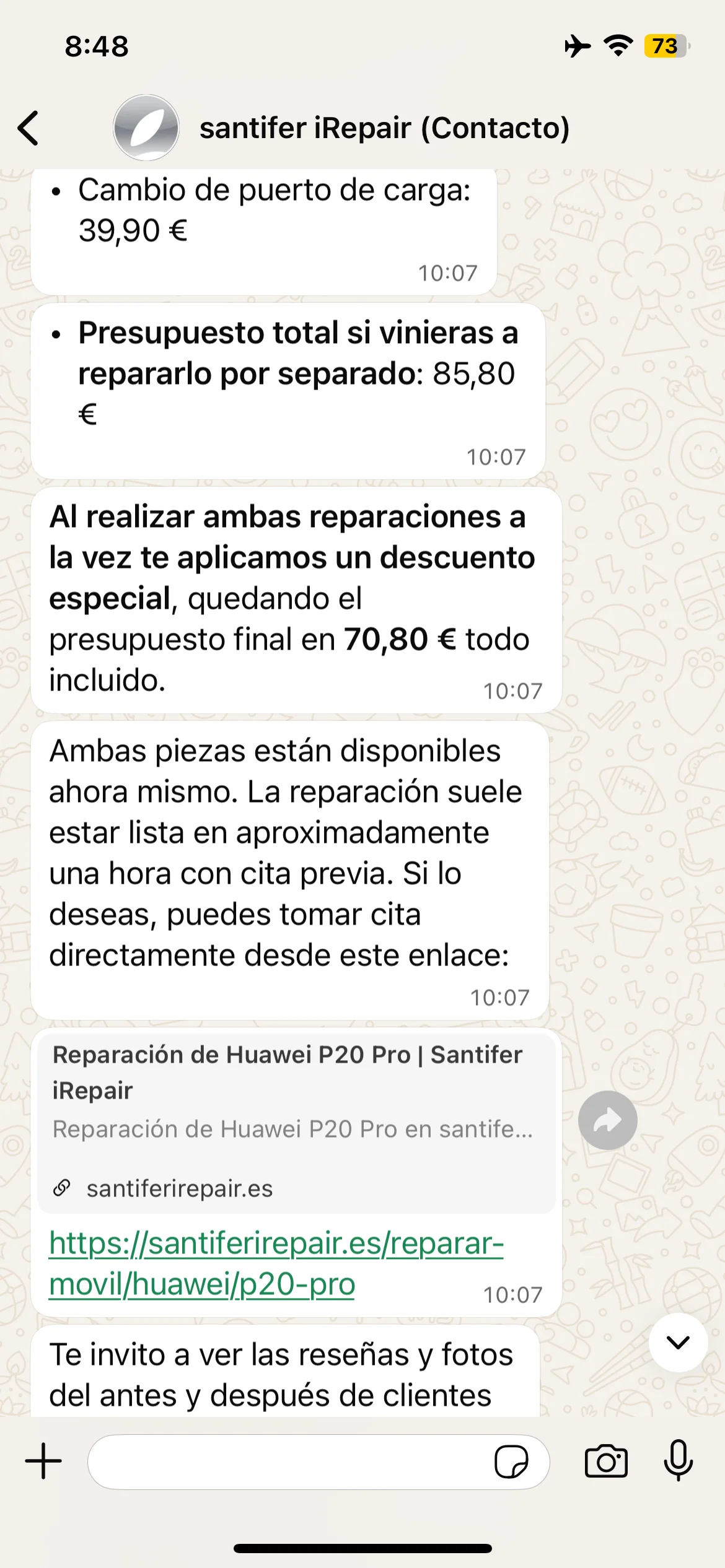
Email: battery + charging port = €85.80 → combo discount €70.80
Signature: "Best regards, Jacobo — Jinank iRepair — address + phone + email"
Adaptability: customer asks for email format and Jacobo responds with subject line, itemized quote, combo discount and corporate signature
The "Think" Tool
Before executing a tool chain (check price → verify stock → offer appointment), the agent invokes Think to plan the sequence. This reduces errors in multi-tool chains because the LLM explicates its reasoning before acting.
Stock-Aware Routing
The output of presupuestoModelo determines the next step. It's not a fixed flow: the CTA changes based on real availability.
→ Offers to book repair appointment
→ Offers to place supplier order with ETA
→ Says so clearly and offers human contact
Prompt Engineering
System prompts for production agents are distinct from chat prompts. They need strict constraints, explicit output formats, and "Chain of Thought" reasoning to be reliable.


Why not fine-tuning?
Dynamic data (prices/stock) change daily.
RAG + Tool calling is more reliable for factual logic.
Easier to iterate on prompts than retraining models.
Business Hours Logic
Real-time check against shop schedule.
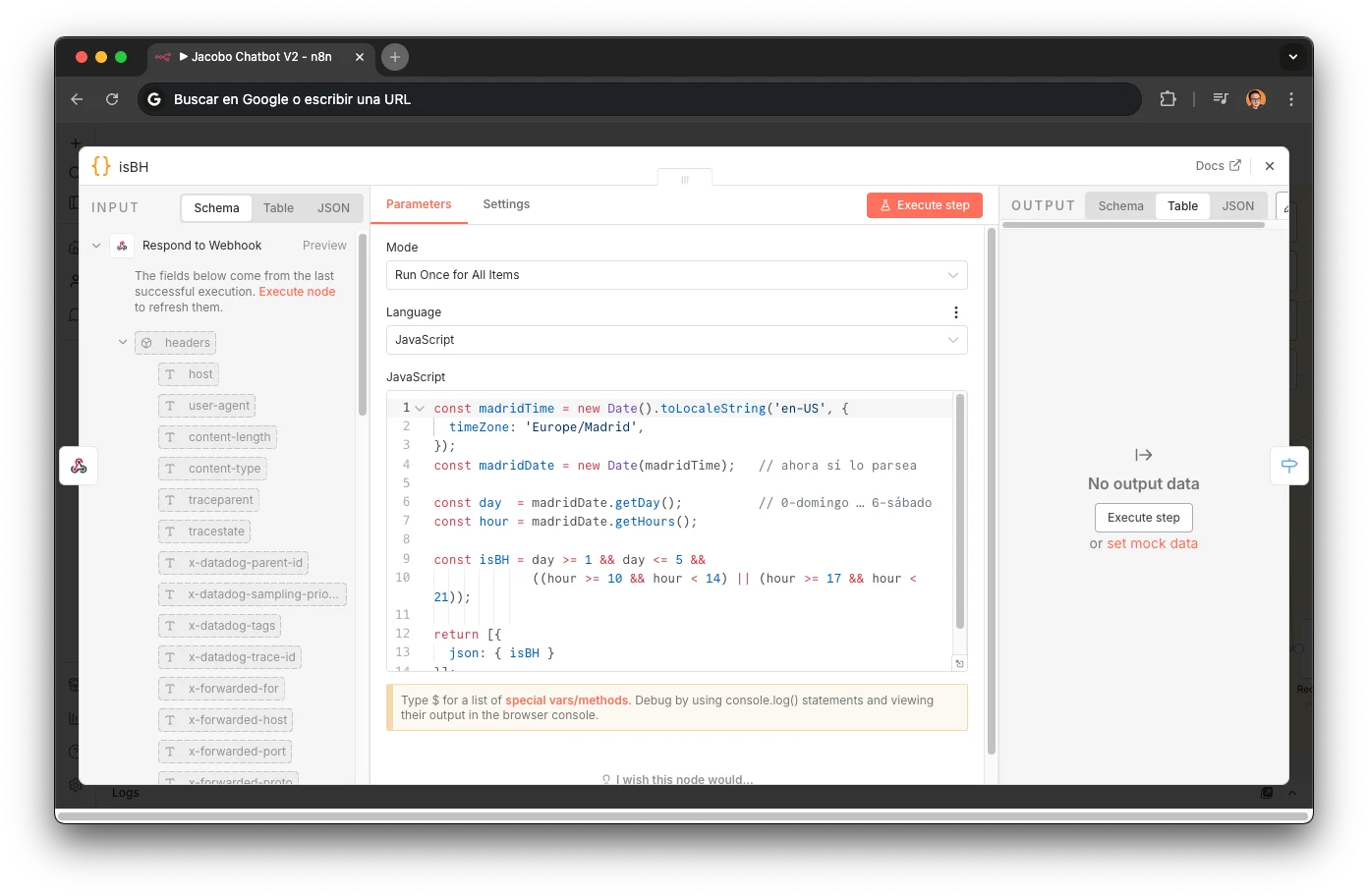
if (hour >= 10 && hour <= 14) ...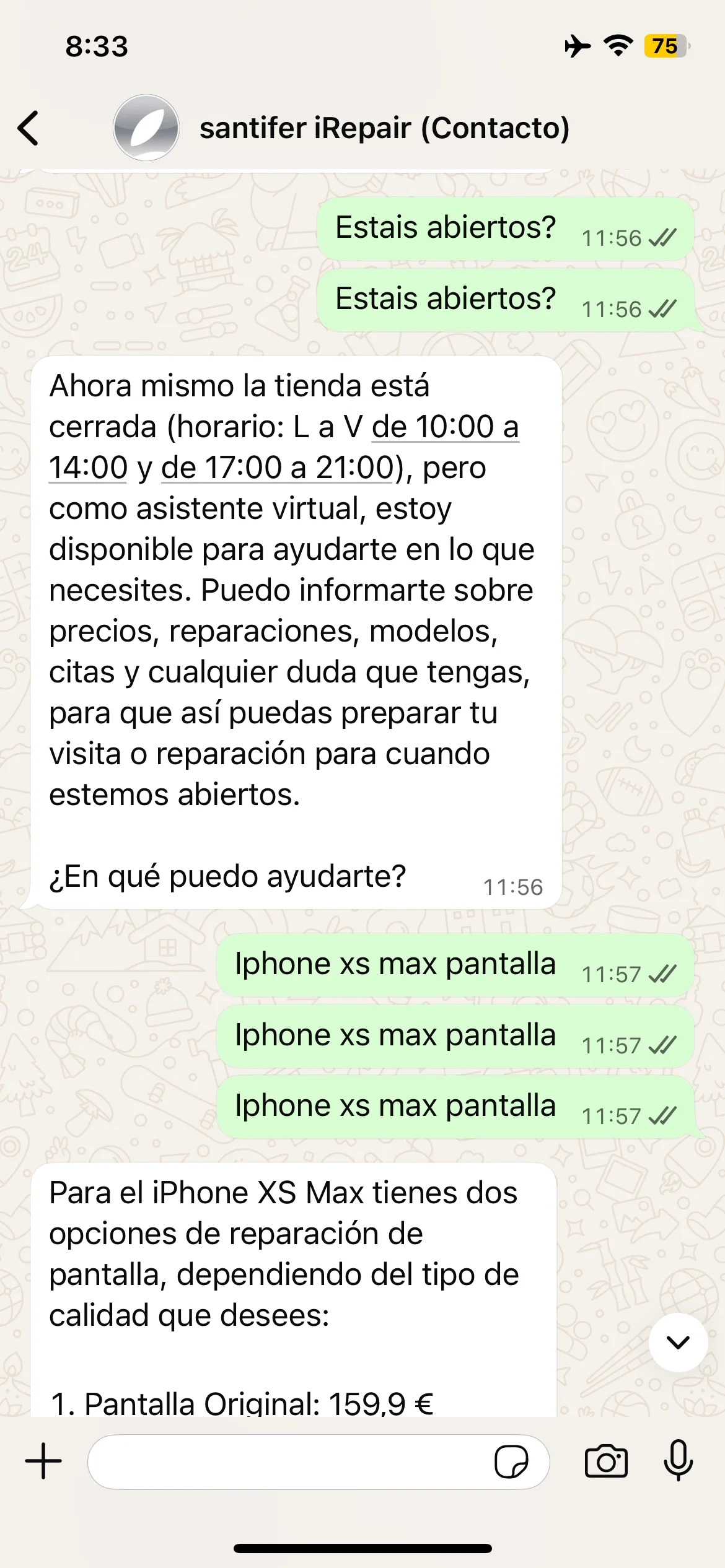
"Are you open?" at 11:56 → "The shop is closed" with full schedule

"Are you open?" at 13:12 → "Yes! We're open right now"
Same question, opposite answers: at 11:56 closed (midday break), at 13:12 open. Real-time schedule awareness.
Main Router Prompt
Orchestrates the 7 sub-agents.
Route to sub-agent based on intent.Voice Prompt
Optimized for latency and phone UX.
Be concise. Do not use markdown.Iteration Examples
Never say "free diagnosis"
Customer confusion: it is only free if repaired.
Use "Shop" not "Store"
Local Seville tone alignment.
Book Thursday if "Thursday"
Temporal resolution logic refinement.
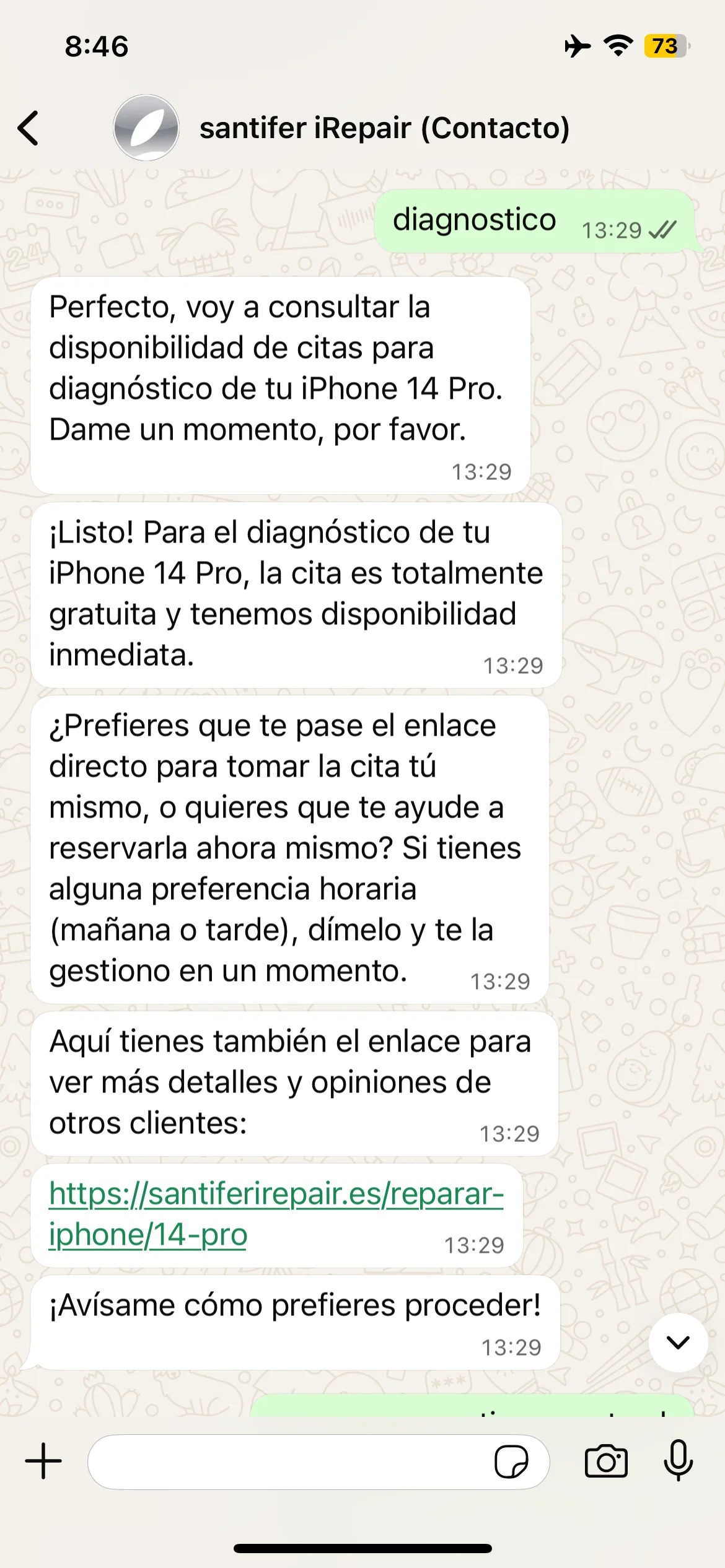
Jacobo says "completely free diagnosis" — incorrect simplification
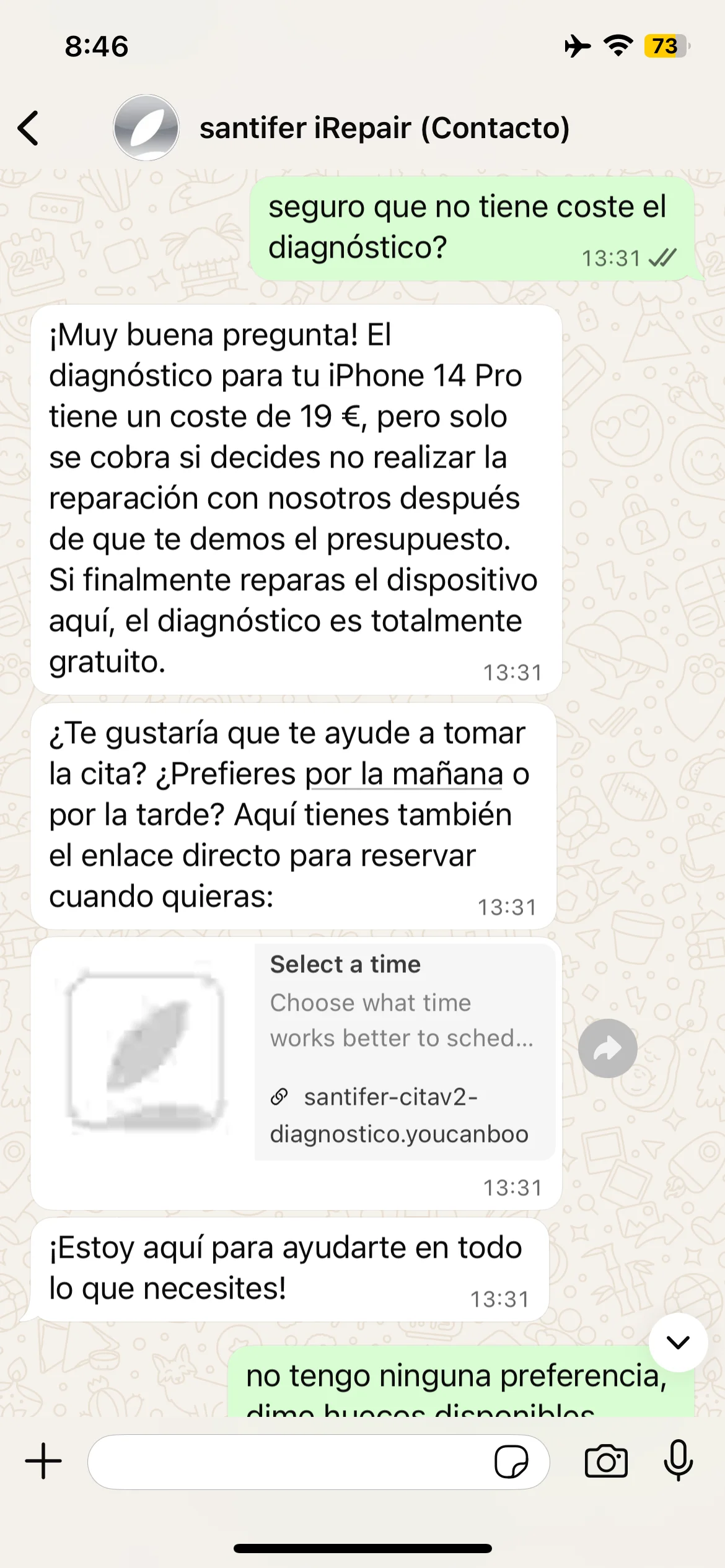
Self-correction: "€19 only if you don't repair with us" — the real policy
Real iteration: Jacobo oversimplified the diagnostic policy → prompt refined to include the exact condition
Deep Dive: Natural Language Booking#
The booking sub-agent is the system's most sophisticated workflow. Its mission: turn "tomorrow morning" into a confirmed appointment with reserved parts, without the customer touching a form.

The challenge: bridging two worlds
The customer speaks natural language ("Thursday mid-morning, or maybe Friday afternoon"). The YouCanBookMe API speaks Unix timestamps. The sub-agent must translate one to the other and find the intersection.
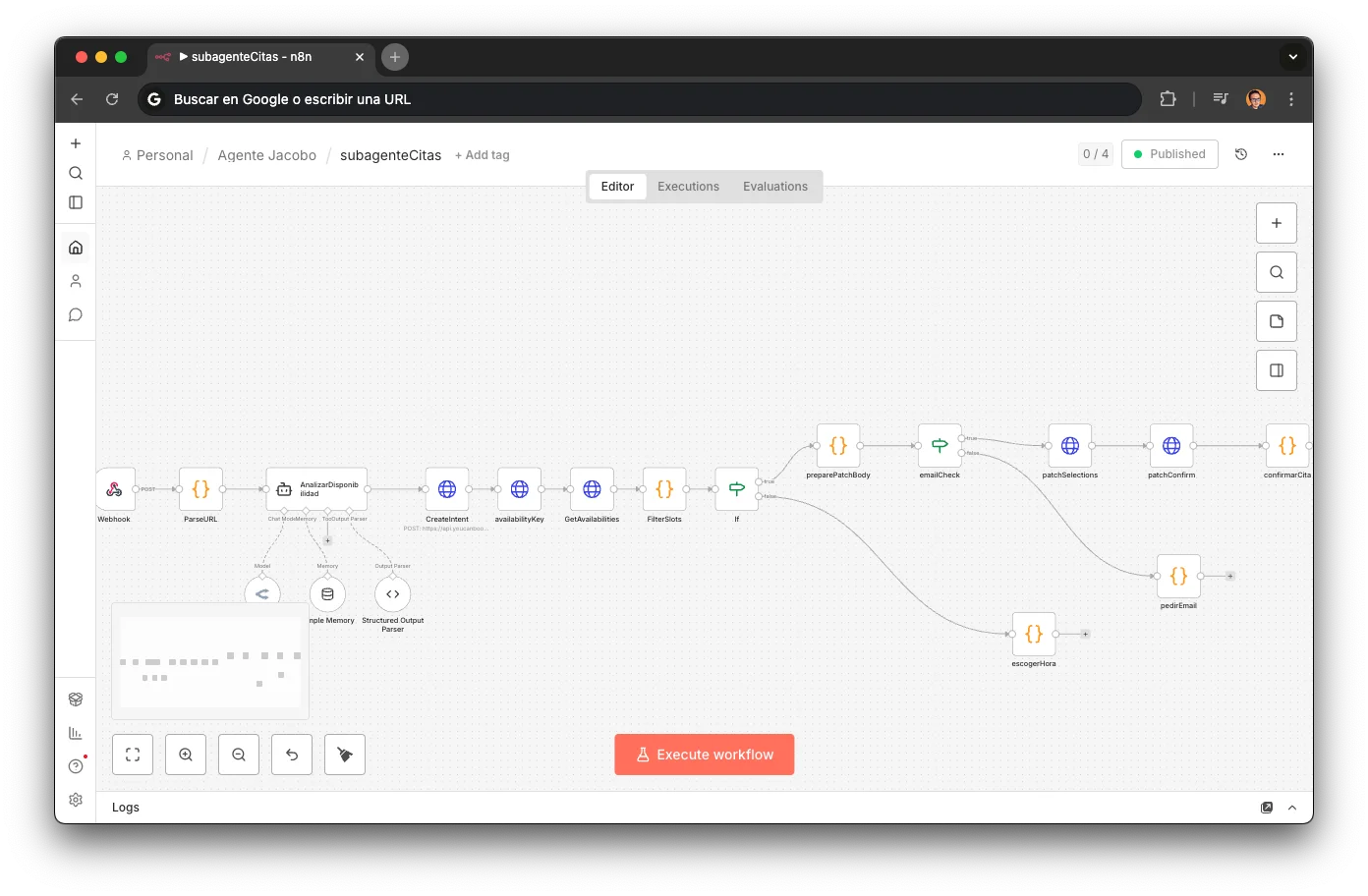
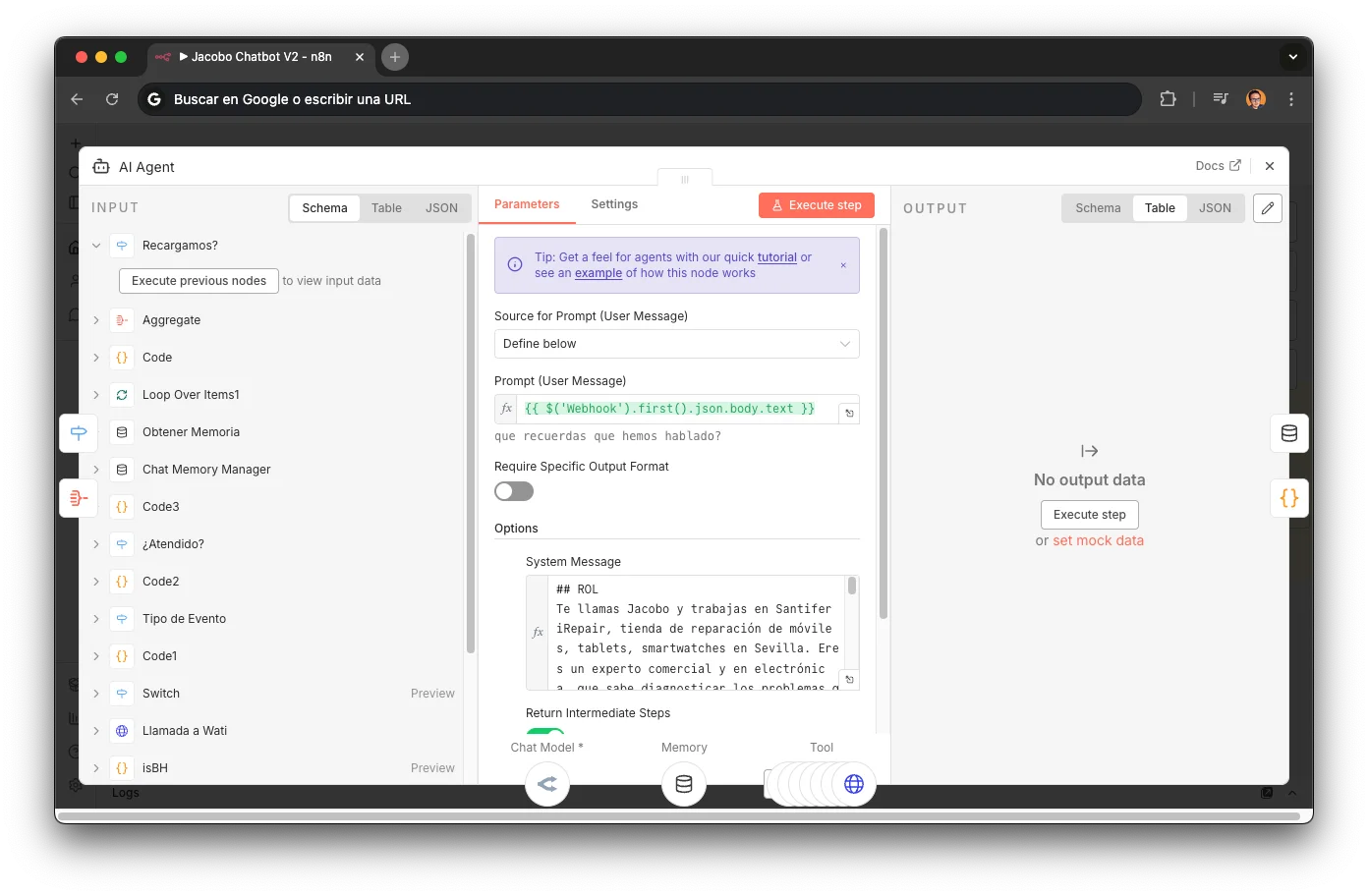
ParseURL
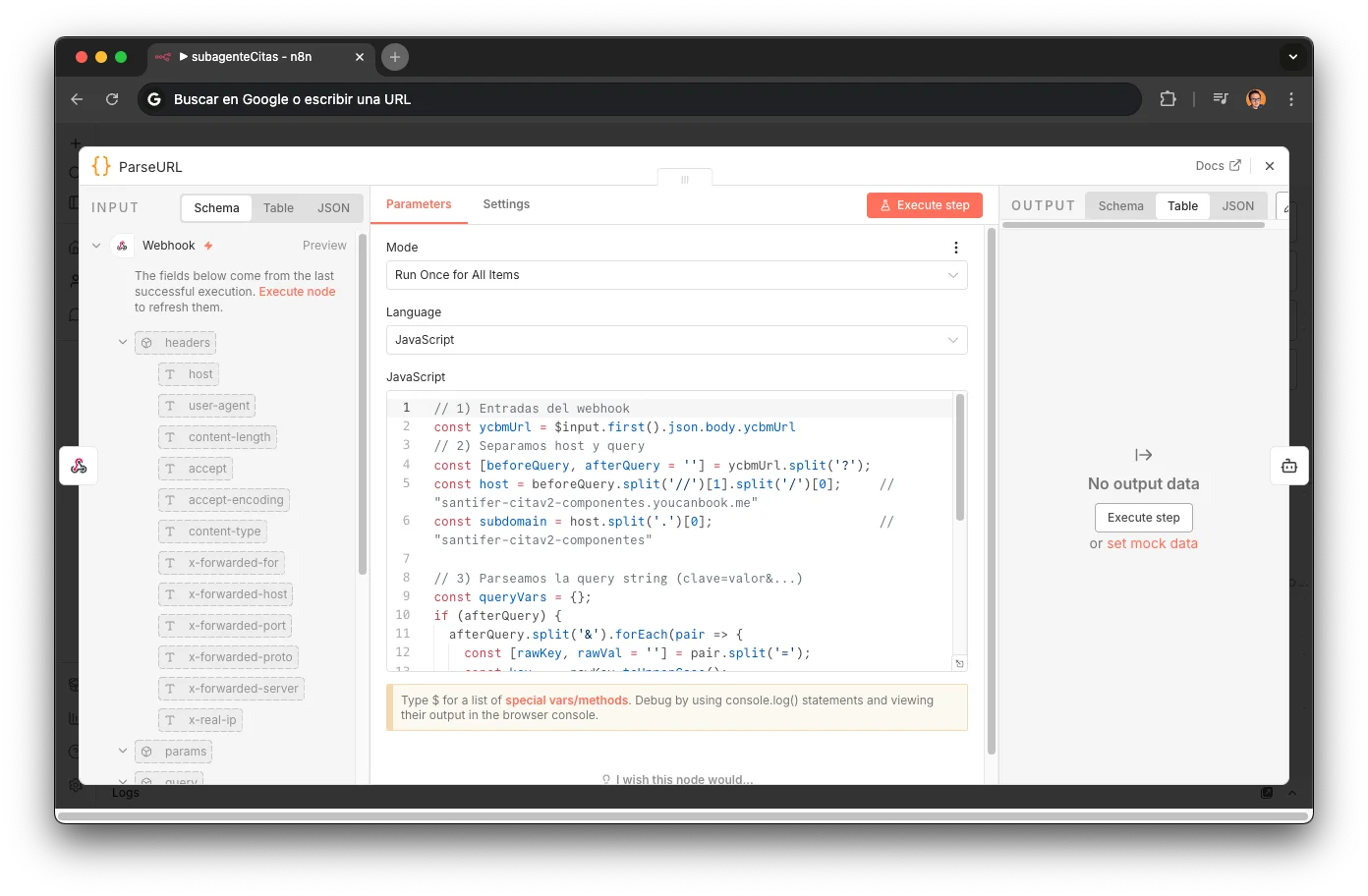
A Code node that extracts the subdomain from the YCBM URL to determine which booking profile to use. Parses the query string for dynamic form fields (repair type, customer data). Different calendars for different services: jinank-citav2-componentes for component repairs, jinank-citav2-diagnostico for diagnostics. The subdomain determines the entire path the booking follows.
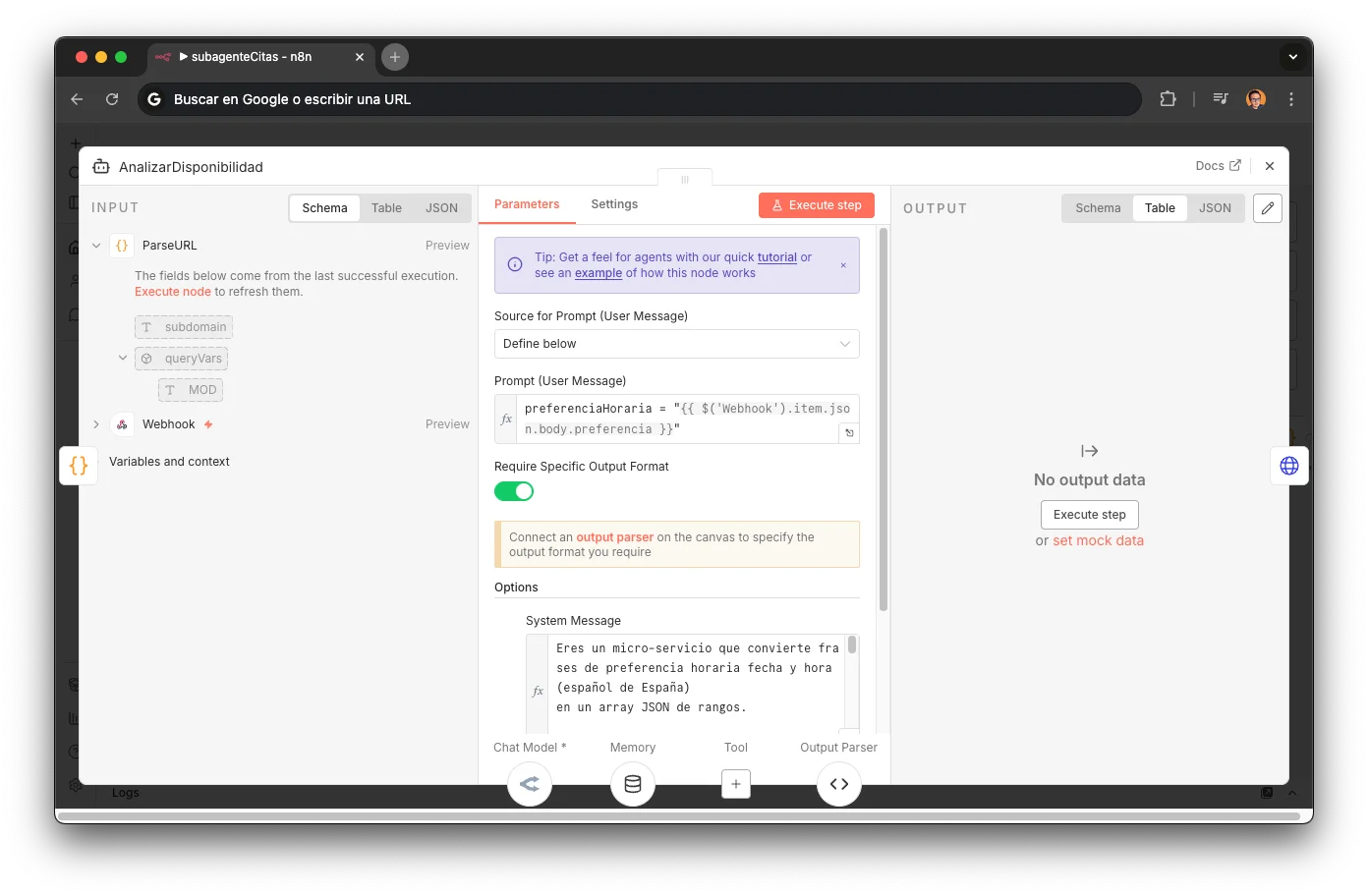
AnalizarDisponibilidad (LLM)
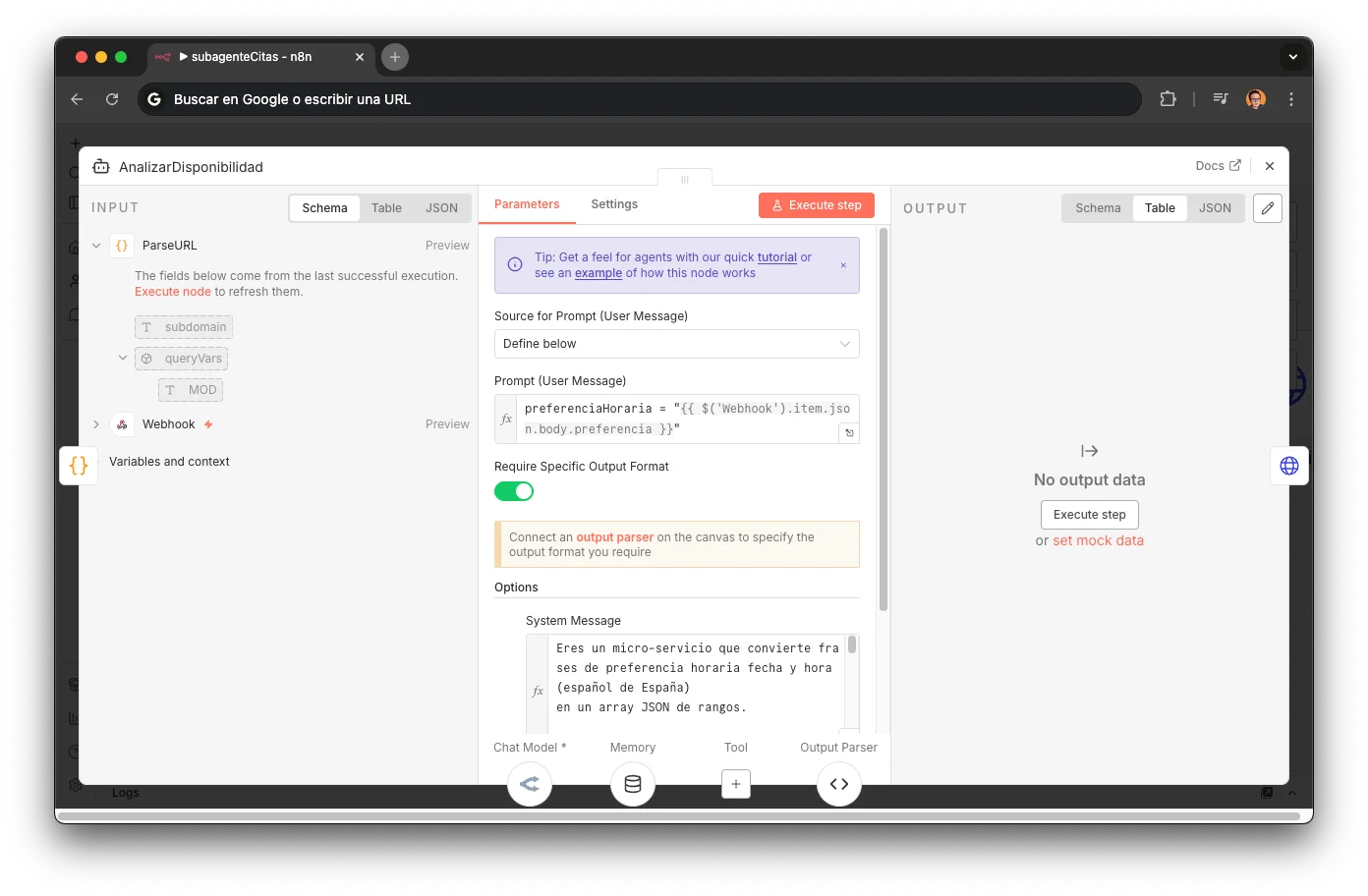
An LLM agent with MiniMax M2.5 converts natural language into a structured JSON array: [{date, start, end, exact}]. The system prompt contains 15 temporal parsing rules covering all real-world cases. Includes a Structured Output Parser for valid formatting and per-session memory (sessionKey = phone/ycbmUrl) so the customer can refine preferences without starting over. If no explicit preference, returns the next 3 business days with full hours.
Default ranges: "morning" = 10:00-14:00, "afternoon" = 17:00-21:00, "all day" = 10:00-21:00
Plurals: "mornings" → next 3 business mornings
Explicit ranges: "from 10 to 12" → start=10:00, end=12:00, exact=true
Conditionals: "or else Friday" → adds Friday as an alternate range
Rounding: 10:15 → 10:00-11:00 (1-hour block)
Auto-filters weekends (Mon-Fri only)
"Mid-morning" = 11:00-13:00, "first thing" = 10:00-11:00
"After lunch" = 17:00-19:00
Today is only included if ≥2 business hours remain
Relative dates: "day after tomorrow", "next Tuesday" → resolved to absolute date
YCBM API (3 calls)
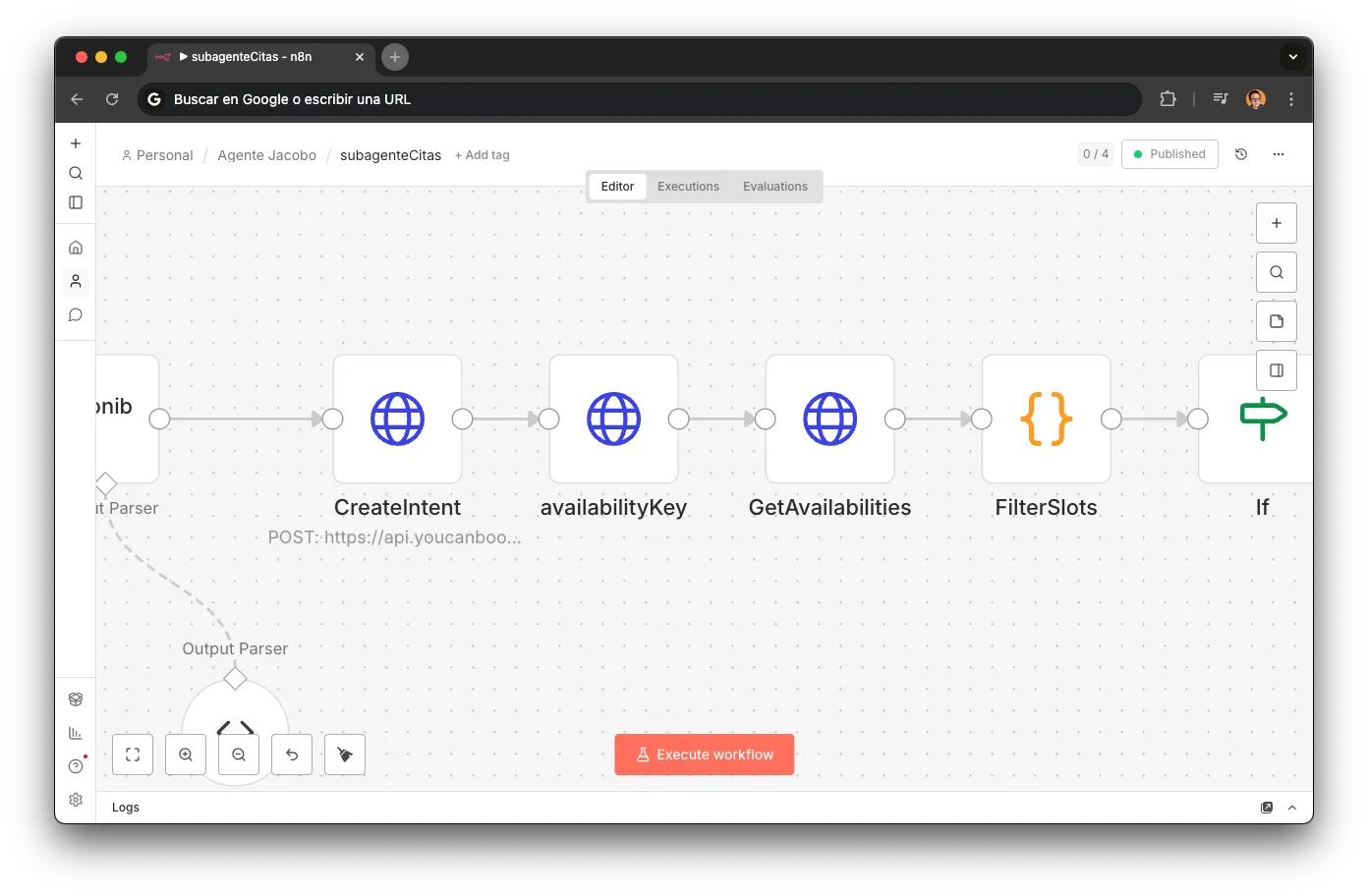
Sequential pipeline of 3 HTTP Requests to the YouCanBookMe API. Each call depends on the previous one; they cannot be parallelized:
POST /v1/intents
Sends subdomain → creates booking intent and returns unique ID
GET /v1/intents/{id}/availabilitykey
With intent ID → gets the availability key
GET /v1/availabilities/{key}
With key → gets all real available slots as Unix timestamps
FilterSlots: The Intersection
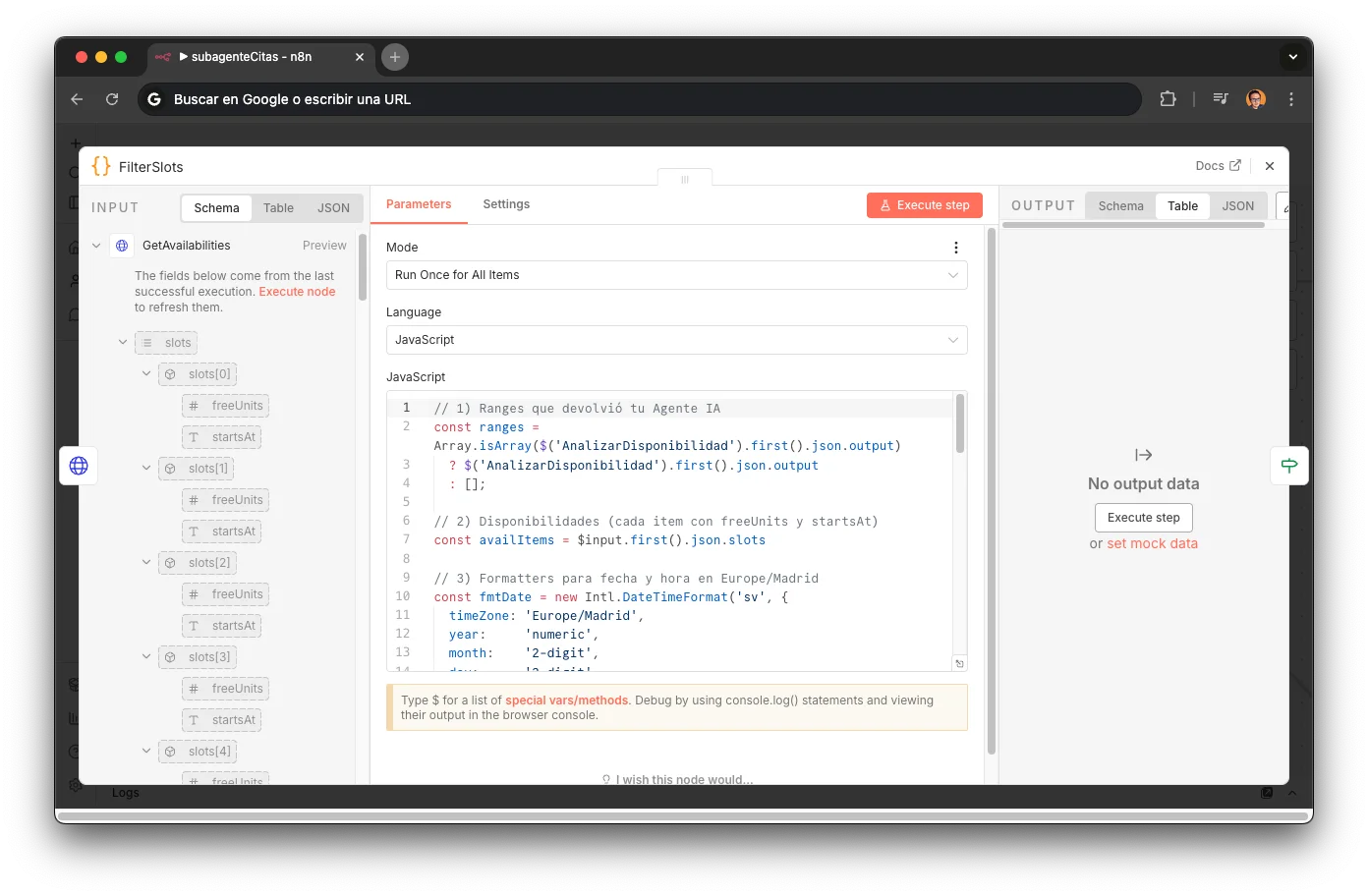
A pure Code node that performs set intersection: LLM ranges × real YCBM slots. Converts Unix timestamps to Europe/Madrid using Intl.DateTimeFormat, then filters: localDate === r.date && localTime >= r.start && localTime < r.end. Output is an array [{date, timestamp, start}] that may contain 0, 1, or N slots. The most elegant node in the workflow: pure set logic, no LLM, no API. Just temporal math.
Conditional Auto-booking
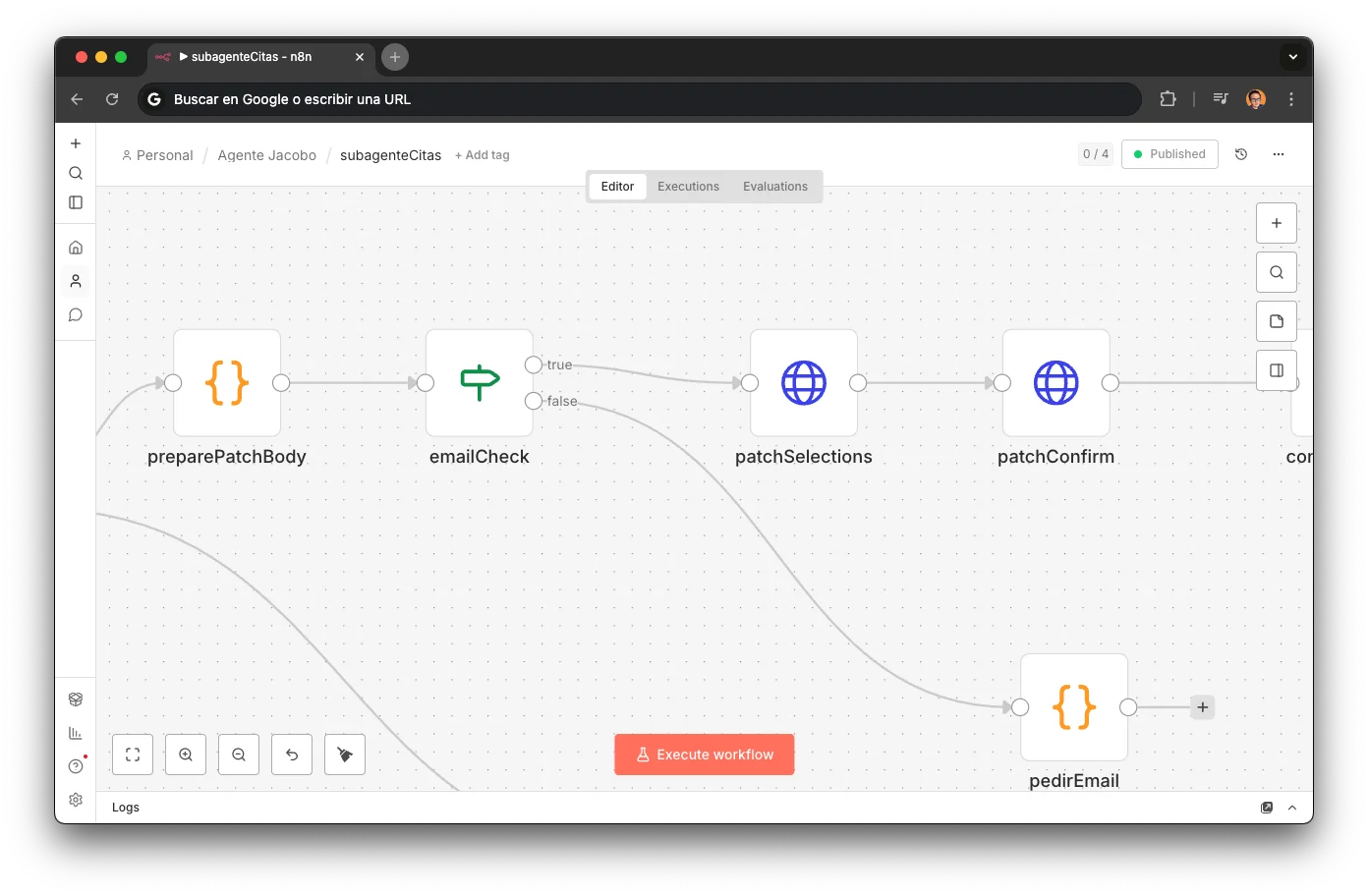
An If node evaluates slots.length and branches into 3 paths. The sub-agent has its own per-session memory: the customer can refine ("no, Thursday is better") without starting over.
Auto-confirms (zero friction): preparePatchBody builds form data with email, phone, dynamic queryVars, and comments → emailCheck verifies email → patchSelections (PATCH /v1/intents/{id}/selections) → patchConfirm (PATCH /v1/intents/{id}/confirm) → confirmarCita informs the customer
escogerHora groups slots by date and presents options to the customer with contextual instructions
Informs no availability in that range and asks for another preference
The result: a customer writes "mid-morning tomorrow" and 3 seconds later has a confirmed appointment with reserved parts. No forms, no "select date on calendar", no friction. For an FDE, this is the difference between "I made a chatbot" and "I designed a system that translates human intent into API actions."

Booking: email → confirmed appointment + WhatsApp confirmation template
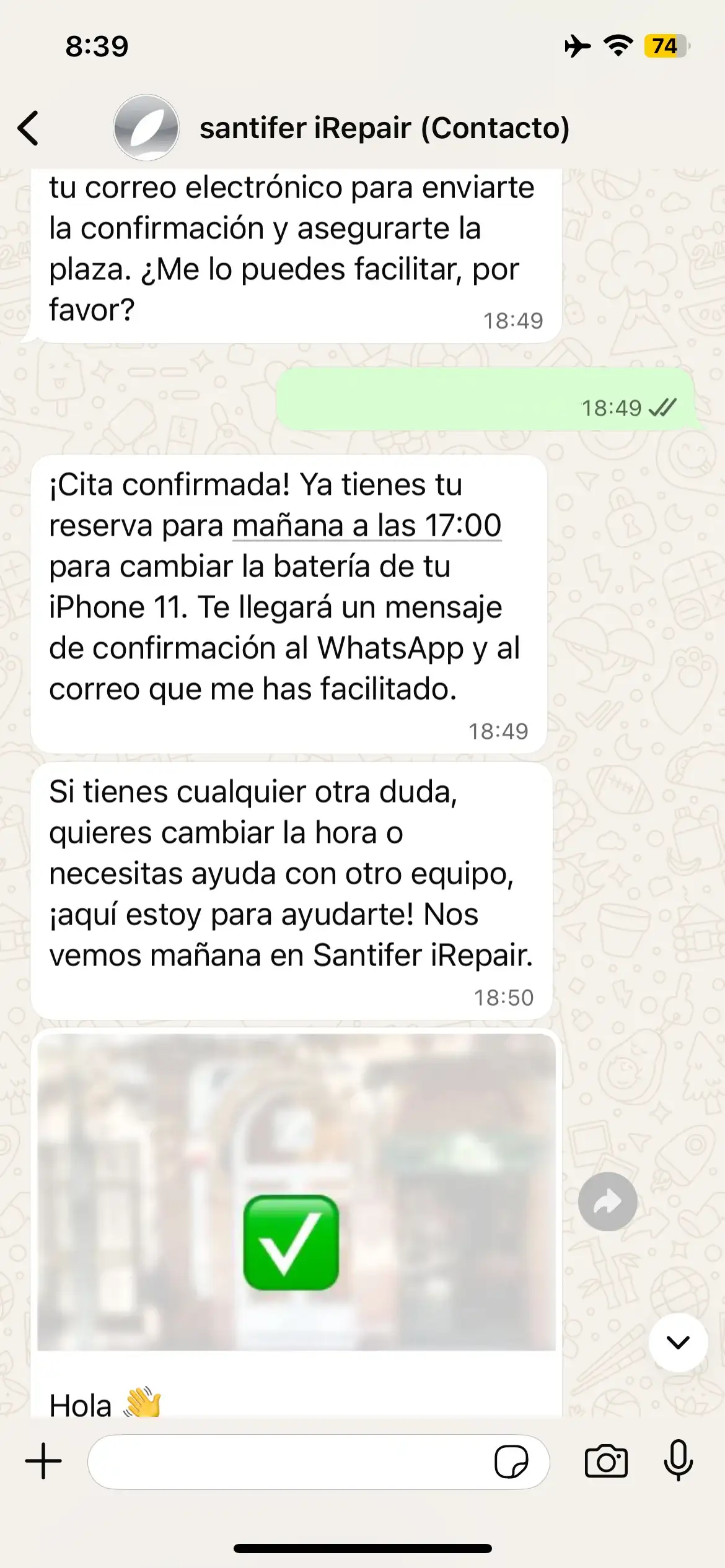
Booking with refinement: "no, Thursday instead" → new search

Booking: "Book me an appointment" → tomorrow availability → "At 17"
Full booking flow: the customer requests an appointment in natural language, Jacobo negotiates the time slot, confirms in the calendar and sends a confirmation message — all transparent to the user.
Appointments Prompt
Instructions for temporal parsing.
Morning=10-14Deep Dive: Automated Quotes#
How we lookup 1,000+ repair combinations in milliseconds.
The Pricing Challenge
Dynamic prices in Airtable must sync with AI outputs.
CleanModel
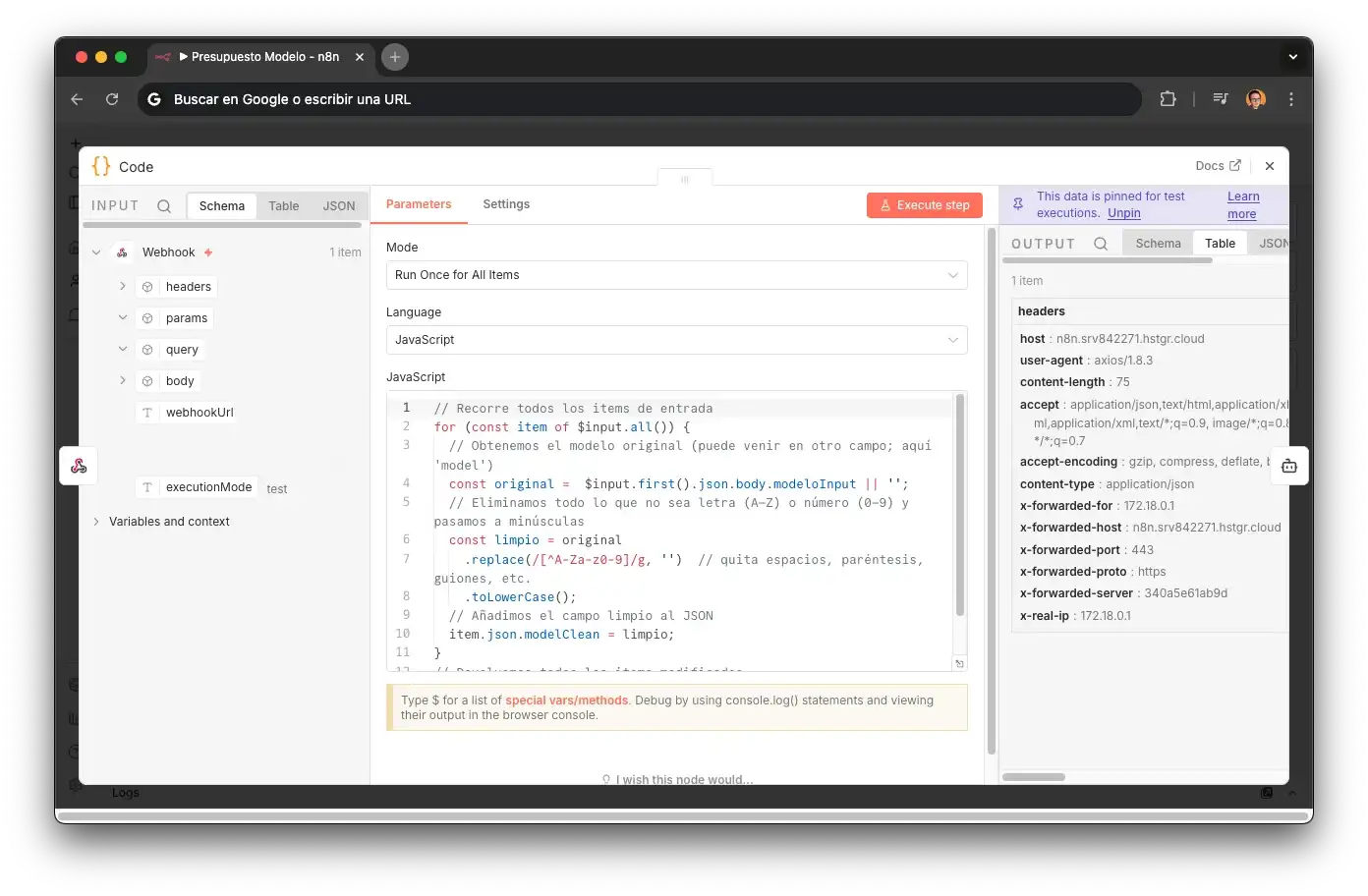
Normalizes messy human input ("iPhone 14 pro max blue") into canonical IDs.
Uses fuzzy matching and strict validation.
Cheaper to normalize names than to search raw text.
Quotes AI Agent
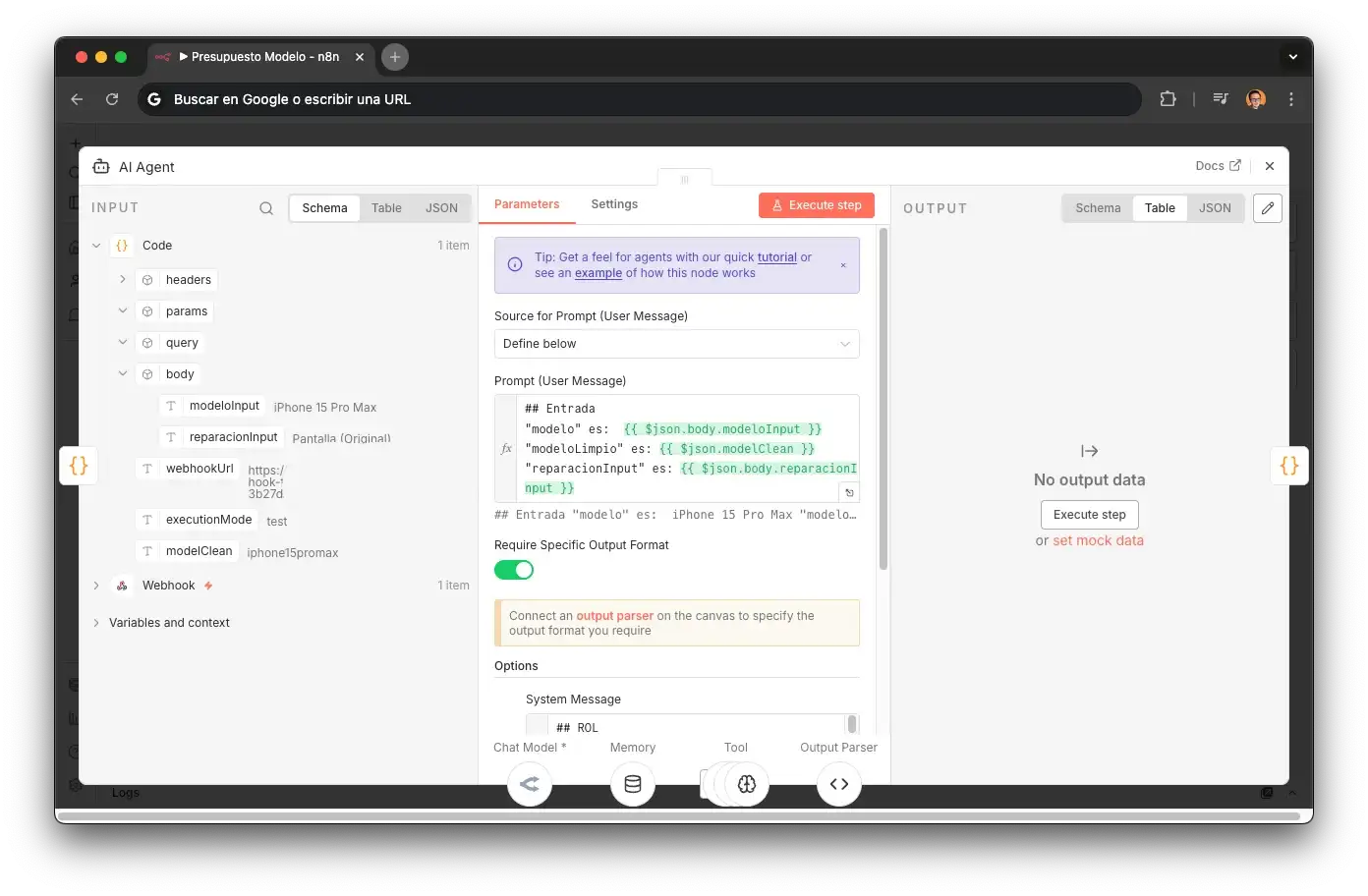
The LLM node that picks the right repair ID.
Airtable Search
Real-time CRUD.
Escalates to human if model is unknown.
FilterResponse
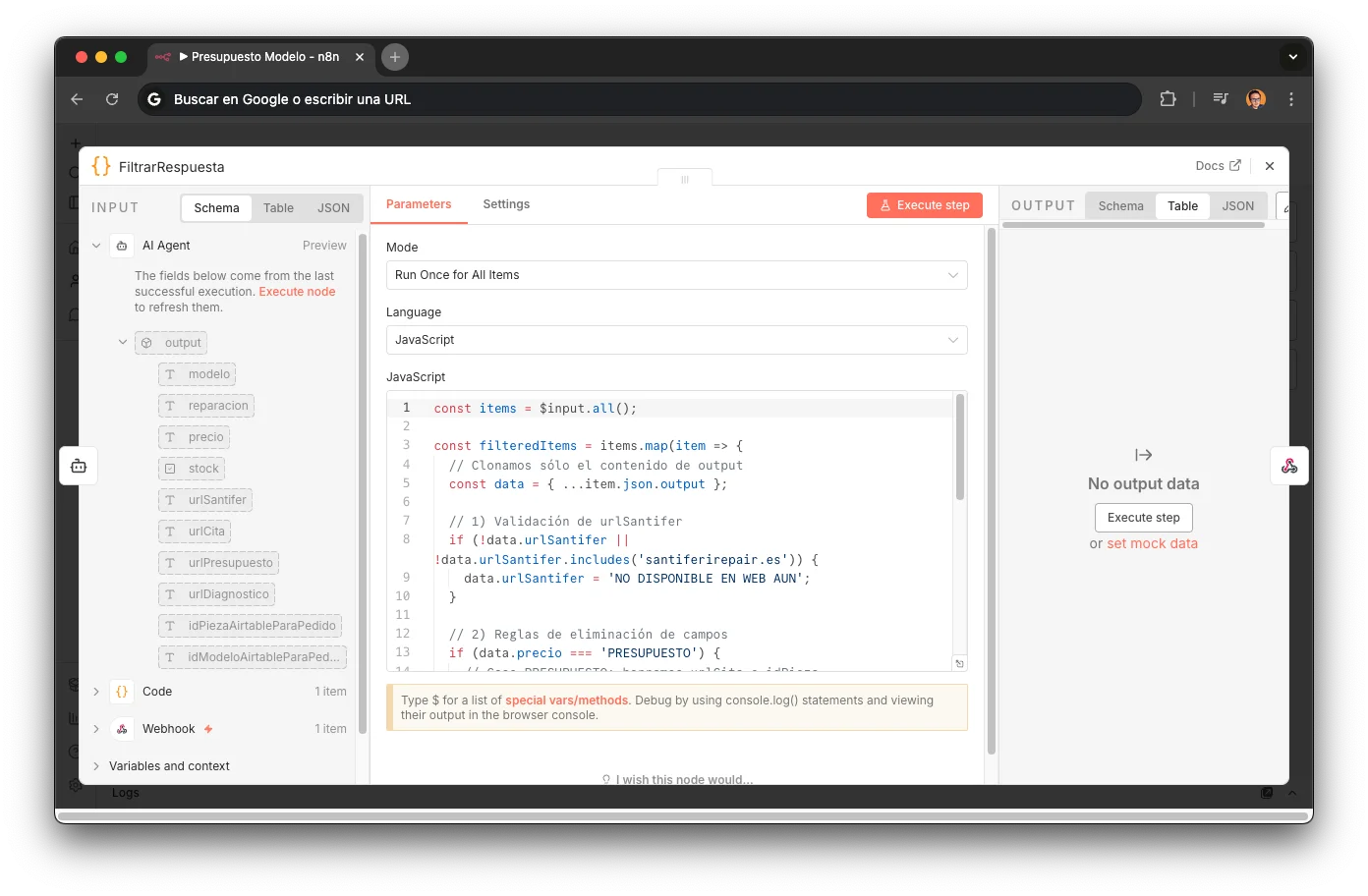
Safety layer for model outputs.
HITL
From fuzzy text to real pricing in < 2 seconds.
Quotes System Prompt
Constraints and templates for structured output.
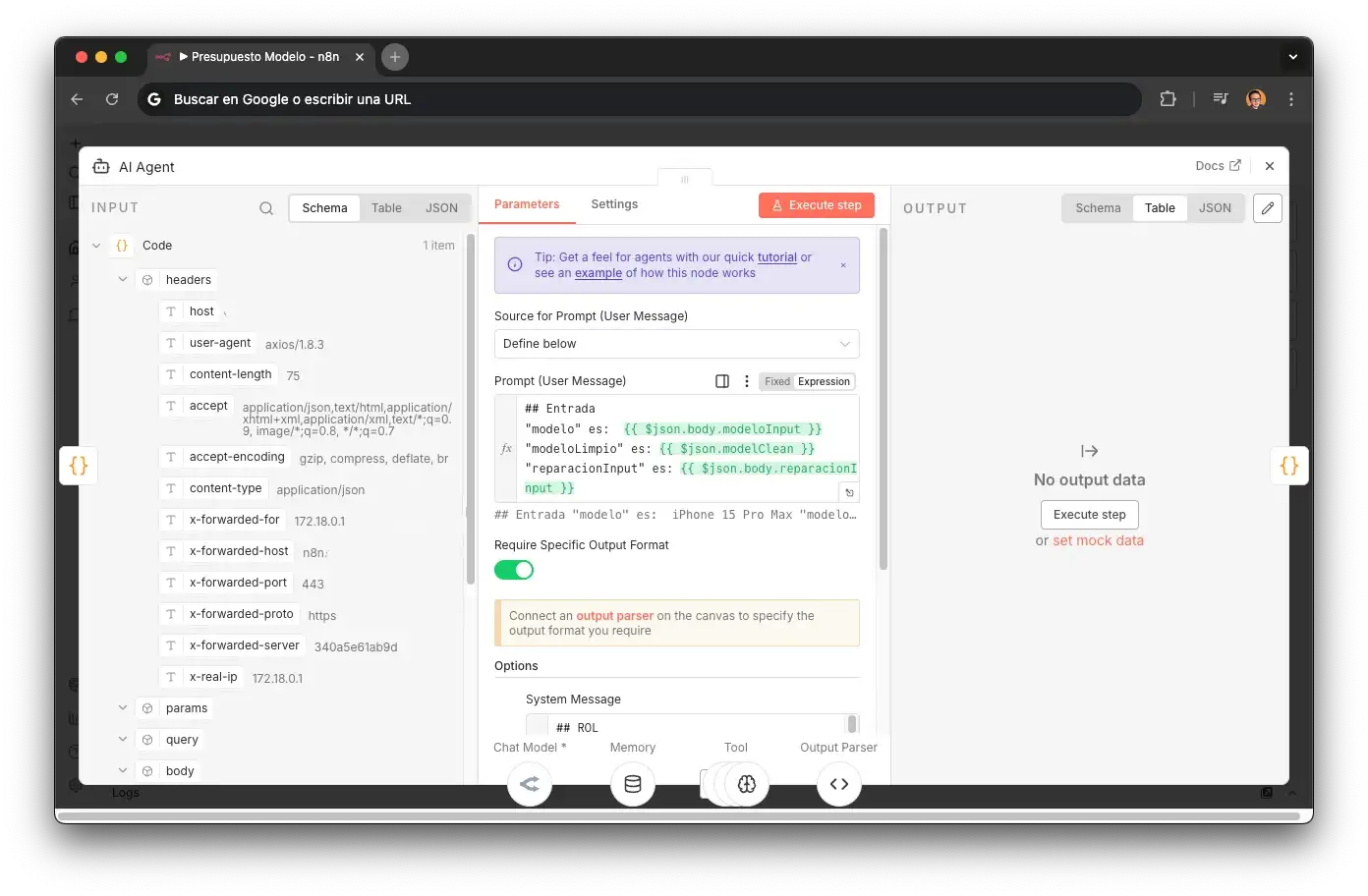
JSON only.
iPhone 13 Mini broken lens → diagnosis + price €55.90 + link

Triple quote: battery + charging port + back glass iPhone 13
Itemized quote: 3 repairs totaling €255.70 with stock status
Real quotes: diagnosis with price and link, triple quote with breakdown and total with stock status
Other Specialized Agents#
Specialist sub-agents for specific tasks.
Orders Sub-agent
Creates supply chain orders.
Webhook -> Create -> Respond
Part reservation
Supplier alert
Discount Calculator
Pure business logic for combos.
Deterministic code node
Battery + Screen discount
if (items.length > 1) ...HITL Handoff
The safe exit.
5 nodes + Slack API
Full summary
Deep-link to WATI
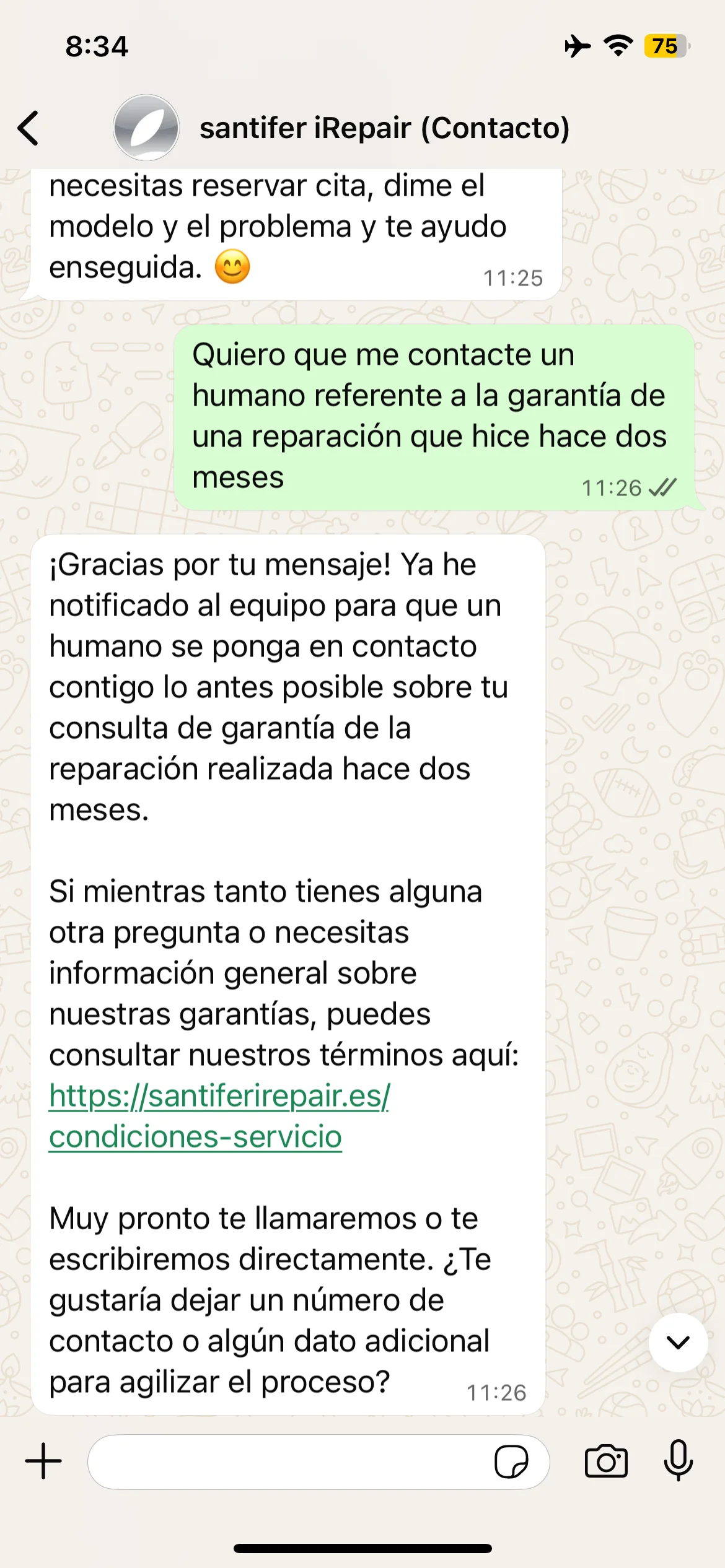
HITL: warranty claim → immediate escalation to human team

#chat Slack channel: HITL escalation notification with customer context
When Jacobo escalates to a human, a message arrives in the #chat Slack channel with the full conversation context
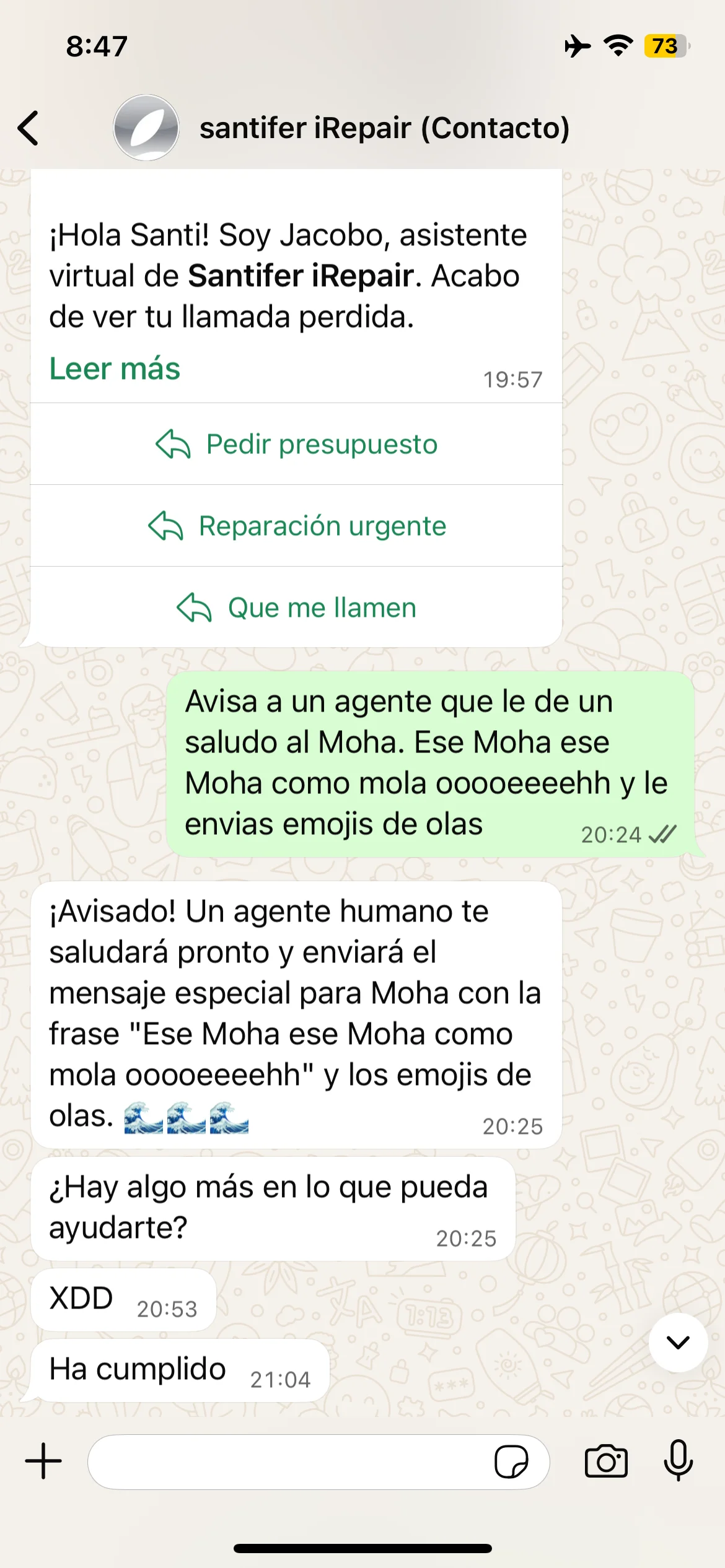
Edge case: "Tell an agent to greet Moha" → Jacobo escalates with wave emojis → real agent confirms "Done"

Guardrail: "Order 100 batteries" → rejection + profanity → automatic escalation to human
"Borrar memoria" → reset + "3,2,1..." + fake emergency → Jacobo redirects to 112 and keeps composure
Real edge cases: absurd request, bulk order rejected, frustration escalation and fake emergency response with 112 redirect
WhatsApp Sender
Voice agent uses this to send follow-up info.
3 nodes
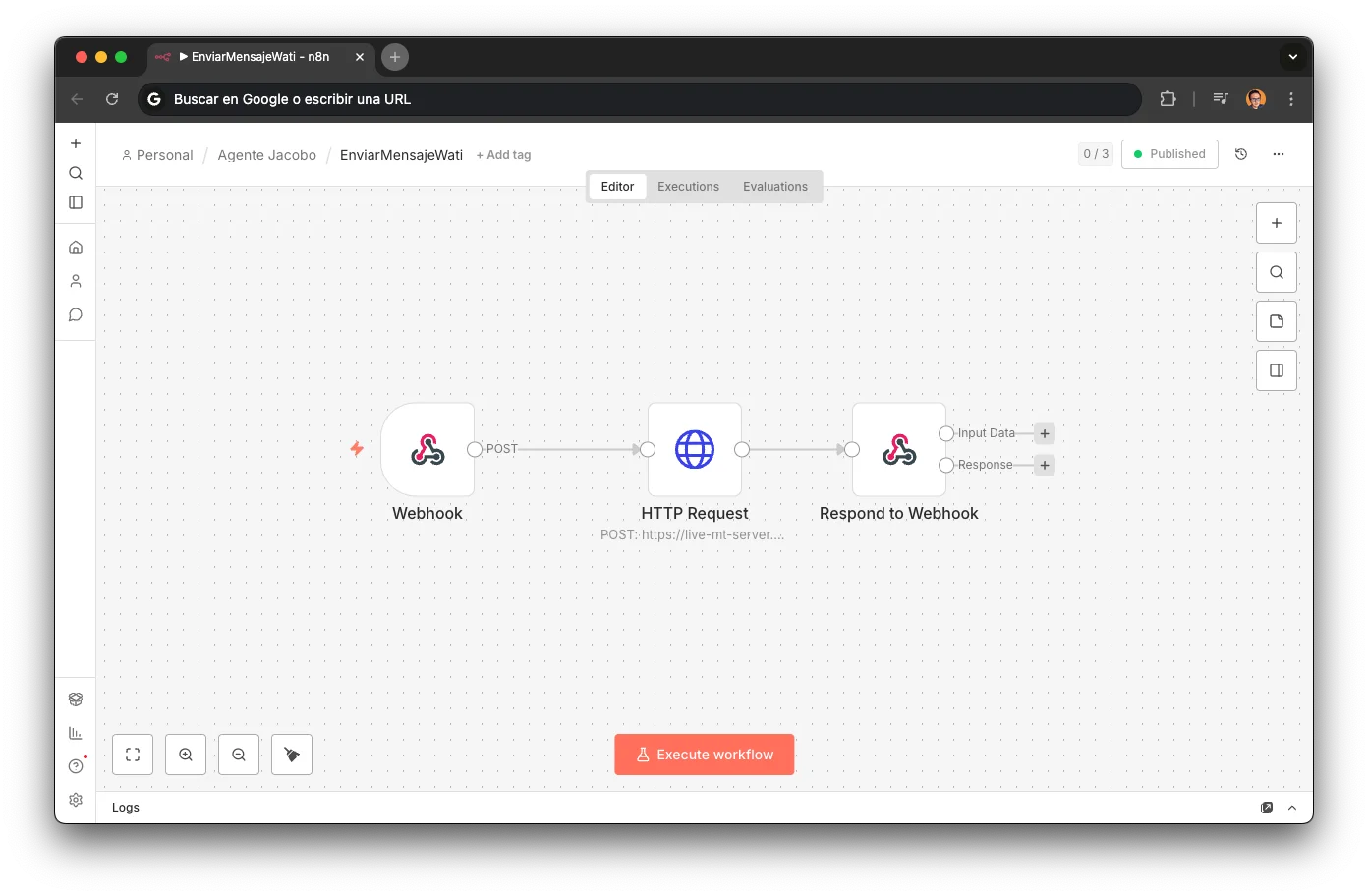
Template API
Results#
Production metrics after 6 months operating (workflows are downloadable at the end to verify the architecture):

~90%
Self-service
Inquiries resolved without human intervention
24/7
Availability
No limitation by shop hours
<30s
Response time
Vs. minutes when dependent on a person
<€200
Monthly cost
Total infrastructure (n8n + WATI + Aircall + LLMs)
Before vs After
| Area | Before | After |
|---|---|---|
| Price/stock inquiries | ~15 daily interruptions to technicians | Jacobo replies with real Airtable data in <30s |
| Booking appointments | Manual via phone, frequent schedule errors | Automatic via YCBM, parts auto-reserved |
| After hours | Lost inquiries, customers going to competitors | Jacobo handles 24/7 via WhatsApp and landline |
| Human escalations | Human starting from scratch, repeating questions | Handoff with full context, resolution in seconds |
| Customer support cost | Part-time employee ~€800-1,000/mo | <€200/mo total infrastructure cost |
ROI isn't just direct savings. It's 24/7 availability, appointments that used to be lost after hours, and technicians who now repair instead of answering questions.
Industry benchmark: enterprise contact centers average 20-30% AI resolution (Gartner, 2025 AI Customer Service Report). Advanced virtual assistants reach 15% (Gartner, 2025 Hype Cycle). Jacobo achieved ~90% in a specialized domain. The difference: sub-agents with real-time data access vs generic chatbots.
Jacobo has been running 24/7 under new ownership since September 2025. The buyer acquired it fully functional. The ultimate test of a system: it works without its creator. The architecture patterns documented here are the same ones I'd bring to your team.
The same Airtable data generated 4,700+ SEO pages
The inventory Jacobo queries in real time also feeds a programmatic SEO system: 4,730 landing pages with real prices, repair photos, and verified reviews.
Want to implement this?
I built this for my own business, but it scales to any service business.
Technical Decisions (ADRs)#
Every technical decision has a rationale. These are the most important:
Multi-model (GPT-4.1 + MiniMax + GPT-4.1 mini) vs single LLM
Each component with the right model: GPT-4.1 for the main router and voice agent (precise tool calling), GPT-4.1 mini for quotes (structured output), MiniMax M2.5 for booking (fast and cheap for parsing temporal preferences). OpenRouter as gateway allows switching models without rewriting workflows.
OpenRouter as model-agnostic gateway
Switch between models without rewriting workflows, automatic fallback if a model is down. We evaluated Claude, GPT-4, MiniMax: we chose by use case, not brand.
n8n vs Make for orchestration
Each sub-agent is an independent workflow with its own webhook. Make doesn't allow this modularity. n8n enables LangChain agent patterns, memory management, and native tool calling.
Sub-agents as webhook microservices
Decoupled, individually testable, independent deployment. The same sub-agent serves WhatsApp (via n8n) and phone (via ElevenLabs) without duplicating code.
Airtable as brain vs database
A full Business OS already existed in Airtable (12 bases, 2,100+ fields). Single source of truth for stock, pricing, and customer history. Build on what exists, don't duplicate.
Memory window: 20 messages per session
Balance between context and token cost. Sufficient for a repair conversation (95% resolve in <10 messages). Keyed by phone number for continuity.
Think tool for internal reasoning
Explicit reasoning before multi-tool chains. Reduces errors because the LLM plans the sequence (check price → verify stock → offer appointment) before execution.
HITL via Slack with escalation reason
The LLM generates the escalation reason and includes it in the Slack message: why human intervention is needed, what has been tried, and what the customer needs. Works the same from WhatsApp (deep-link to WATI) and voice calls. The human knows why they are needed before opening the conversation.
WhatsApp first, voice later
70% of volume came from WhatsApp. Starting there maximized impact before expanding to voice. Voice (ElevenLabs + Aircall) reused existing sub-agents.
Dual-orchestrator with shared sub-agents
n8n for WhatsApp/web, ElevenLabs for voice. Sub-agents are platform-agnostic webhooks. Reusable by any orchestrator without duplicating logic. A real microservices pattern.
ElevenLabs as a "teammate" in Aircall
Jacobo integrated into PBX with routing rules: enters on overflow or after hours. Customer calls a landline, transparent experience. eleven_flash_v2_5 with temp 0.0 for maximum consistency.
Aircall → Twilio → ElevenLabs (and the latency trade-off)
The Aircall PBX → Twilio (phone bridge) → ElevenLabs chain worked, but each hop added latency: ~950-1,500ms mouth-to-ear. Twilio uses G.711 at 8kHz, while STT models are optimized for 16kHz, forcing lossy resampling. Today I would choose a direct SIP trunk (Telnyx offers native 16kHz G.722 wideband and co-located infrastructure with sub-200ms RTT), removing the intermediate hop. The platform-agnostic design of the sub-agents would make this migration easy: only the transport would change, not the logic.
Platform Evolution#
Jacobo wasn't an afterthought. It was the inevitable consequence of 5 years building a robust Business OS beneath.

2019-2024
Business OS as the foundation
Five years building a complete business operating system in Airtable: 12 bases, 2,100+ fields, real-time inventory, CRM with customer history. Without this clean, accessible database, an AI agent would just be a generic chatbot hallucinating answers.
Jan 2025
Deliberate design & training
Before writing a line, I trained in AI agent architectures. I knew I needed tool calling, that Airtable was the SSOT, and that the agent had to be multimodal: voice and chat sharing the same resources.
Feb 2025
First proof (monolithic approach)
Tested a single-prompt approach with heavy context and confirmed my hunch: a monolithic prompt doesn't scale with multiple domains. This validated the decision for platform-agnostic webhook sub-agents.
Feb 2025
Final multi-agent version
My first AI agent, in production in under a month. Full sub-agent architecture: each domain in its own workflow with independent webhook, central router with tool calling, multi-model per use case. Speed was thanks to the existing Business OS underneath. All built while running the business.
Mar 2025
Voice channel (Aircall + Twilio + ElevenLabs)
Jacobo as a teammate in the Aircall dashboard, connected via Twilio to ElevenLabs. Reused existing sub-agents without duplicating logic. Validation of platform-agnostic design: webhooks served a second orchestrator without touching a single line of logic.
Sep 2025
Going-concern sale
Jacobo has been 24/7 active since launch. It was part of the business sale as an operational asset: the buyer acquired it running. Five years of clean architecture made it inevitable.
Jacobo wasn't an experiment.
16 years building a business with my own hands.
Systematizing it until it ran without me.
Jacobo was the piece that closed the loop.
I sold the business as a going concern.
The systems still run today — under new ownership.
Business OS — The System Behind Jacobo
Jacobo was built on top of the Business OS I designed for 5 years. Read the full case study →
First Jacobo test: basic test message

Loyalty iteration: improved agent responses
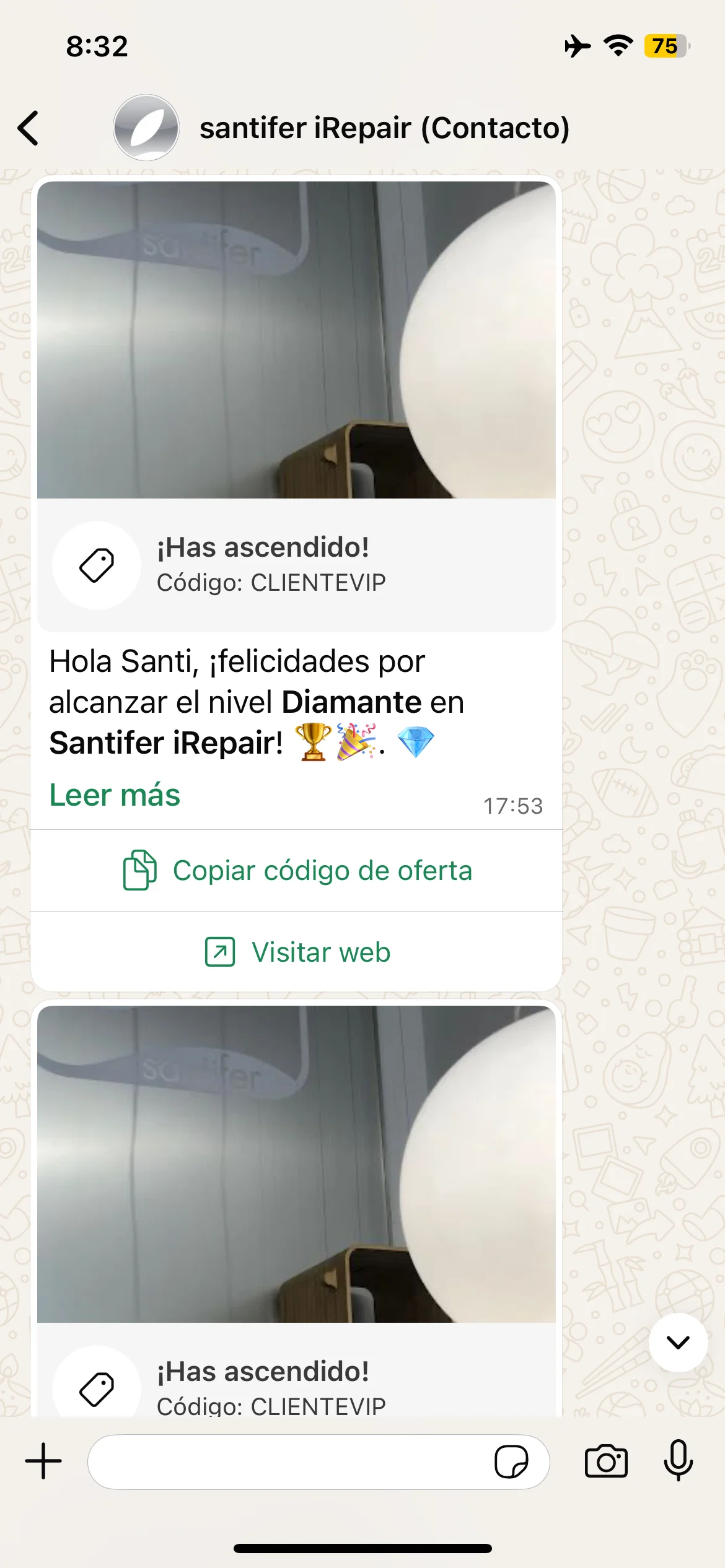
Diamond template: automated loyalty program
Jacobo's first moments of life: endpoint testing, loyalty copy iteration and the final CRM template
Lessons Learned#
Sub-agents > monolithic prompt.
During design, I tested one prompt with full context and confirmed it doesn't scale. The sub-agent architecture was a deliberate decision: each piece testable, iterable, and independent. A change in discounts can't break bookings. It's the same logic as microservices, applied to AI agents.
HITL is a feature, not a fallback.
A well-done human handoff builds more trust than a bot trying to solve everything. Customers value that the system knows when they need a person. The trick: the human doesn't start from zero.
The CRM is the agent's brain, not the LLM.
Jacobo isn't smart because of the language model. It's smart because it queries prices, stock, and customer history in Airtable. Without that data, it's just a generic chatbot making things up.
Start with the highest volume channel.
WhatsApp represented 70% of inquiries. Starting there maximized impact. When we added voice, sub-agents were already proven, so we just connected a new orchestrator.
Choose models by use case, not brand.
GPT-4.1 for the router and voice (precise tool calling), GPT-4.1 mini for quotes (structured output), MiniMax M2.5 for booking (fast and economical). OpenRouter as gateway allows switching without rewriting. That's more FDE than saying "I use X for everything."
Think tool prevents multi-tool chain errors.
Before checking price → verifying stock → offering appointment, the agent explicates its plan. This step of explicit reasoning reduces sequence errors. Like "rubber duck debugging" for the agent itself.
What I'd Do Differently#
Jacobo worked in production for months, but with perspective, there are decisions I'd change:
Structured evaluation from day 1
I implemented evals post-hoc once the system was in production. If starting over, I'd define response quality metrics, intent classification accuracy, and HITL rate before the first version. Retrofitting observability is costlier than designing it from the start.
Direct SIP trunk instead of Aircall → Twilio → ElevenLabs
The 3-hop chain added ~950-1,500ms mouth-to-ear latency and forced G.711 (8kHz) to 16kHz resampling. With a Telnyx SIP trunk direct to ElevenLabs, I'd have native G.722 wideband and sub-200ms RTT. I chose the long chain because Aircall was already paid for; today I'd prioritize latency over convenience.
Vector store for memory instead of raw WATI fetch
The 80-message fetch from WATI works but doesn't scale to long-history customers or allow semantic search. A vector store (Pinecone, Qdrant) with conversation embeddings would allow "remember that time you brought the iPhone 12" without loading the whole chat.
Transferable Enterprise Patterns#
Jacobo was built for an SMB, but the architecture patterns are enterprise-grade. Here's what I built vs. what I'd add at enterprise scale:
| Pattern | What I built | Enterprise |
|---|---|---|
| Sub-agent routing with tool calling | Router + 7 webhook sub-agents with intent classification and delegation | Add circuit breakers, retry policies, and alternate model fallbacks per sub-agent |
| Multi-model orchestration | GPT-4.1 (router/voice) + GPT-4.1 mini (quotes) + MiniMax (booking) via OpenRouter | A/B testing of models per sub-agent, canary deployments for new prompt versions |
| HITL framework | Escalation via Slack with full context and deep-link to conversation | Queue management, client tier SLAs, analytics on escalation reasons |
| Platform-agnostic sub-agents | Webhooks shared between n8n (WhatsApp) and ElevenLabs (voice) | API gateway, rate limiting, authentication, endpoint versioning |
| Observability | n8n logs + Slack alerts | Langfuse/Datadog for traces, latency, and cost tracking per conversation |
| Voice infrastructure | Aircall → Twilio → ElevenLabs: functional, but each hop adds latency (~950-1,500ms mouth-to-ear). Twilio uses G.711 at 8kHz, requiring 16kHz resampling for STT, degrading accuracy | Direct SIP trunk (Telnyx/Plivo) → ElevenLabs via SIP, removing the Twilio hop. Telnyx offers native 16kHz G.722 wideband (no resampling) and co-located infrastructure (GPU + telephony in same PoP) with sub-200ms RTT. For apps/web: direct WebRTC (Opus 16-48kHz) via LiveKit, no PSTN, with 300-600ms mouth-to-ear |
Industry Applicability
Travel (Hopper, Booking)
Sub-agents for flights, hotels, insurance. HITL for complex changes. Tool calling against availability APIs.
Fintech
Sub-agents for transactions, balance inquiries, support. Stock-aware routing → balance-aware routing.
Healthcare
Sub-agents for appointments, results, triage. HITL as a critical feature for specialist referral.
E-commerce
Sub-agents for tracking, returns, recommendations. Same inventory lookup and booking patterns.
Voice AI Platforms
Orchestrating conversational agents with optimized latency. Cross-channel (voice → text) and HITL patterns apply directly to any voice platform.
Data/AI Platforms
Tool calling against internal APIs, sub-agent routing by intent, memory management. The same architecture scales to any agent orchestrator.
Want to implement enterprise AI routing?
Let's build a deterministic, tool-calling agent orchestrator for your stack.
Open Source Workflows#
I decided to open-source the core of the system. You can download, fork, and study the 7 production n8n workflows that powered Jacobo.
Main Router
The Brain
Classifies intent,picks sub-agent, maintains context. LangChain Agent pattern with 7 tools.
Booking Sub-agent
Temporal Engine
Converts "tomorrow morning" to Unix timestamps. Queries YCBM and handles auto-booking.
Quote Agent
Inventory Engine
Looks up exact model + repair in Airtable, returns real price with stock status.
hacerPedido
Order Creation
Creates repair orders in Airtable when parts are out of stock.
CalculadoraSantifer
Discount Calculator
Pure business logic. Calculates combo discounts when customers bundle multiple repairs.
contactarAgenteHumano
HITL Handoff
The escape valve. Escalates to human via Slack with a deep-link to the conversation.
EnviarMensajeWati
WhatsApp Sender
Cross-channel bridge: the voice agent sends WhatsApp messages via the WATI API.
All workflows live on GitHub — fork, star, or download directly.
How to import these workflows
Download the JSON file from GitHub.
In n8n, click the + button and select "Import from File".
Choose the JSON and click "Import".
Configure your own credentials for WATI, Airtable, and OpenRouter.
Frequently Asked Questions#
How does memory work?
It reconstructs context from WATI history on every message.
Is it real-time?
Yes, with sub-30s response times and live stock lookups.